 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Cross-dataset Isolated Sign Language Recognition in Under-Resourced Datasets
Mar 21, 2024



Sign language recognition (SLR) has recently achieved a breakthrough in performance thanks to deep neural networks trained on large annotated sign datasets. Of the many different sign languages, these annotated datasets are only available for a select few. Since acquiring gloss-level labels on sign language videos is difficult, learning by transferring knowledge from existing annotated sources is useful for recognition in under-resourced sign languages. This study provides a publicly available cross-dataset transfer learning benchmark from two existing public Turkish SLR datasets. We use a temporal graph convolution-based sign language recognition approach to evaluate five supervised transfer learning approaches and experiment with closed-set and partial-set cross-dataset transfer learning. Experiments demonstrate that improvement over finetuning based transfer learning is possible with specialized supervised transfer learning methods.
Point Cloud Segmentation Using Transfer Learning with RandLA-Net: A Case Study on Urban Areas
Dec 19, 2023Urban environments are characterized by complex structures and diverse features, making accurate segmentation of point cloud data a challenging task. This paper presents a comprehensive study on the application of RandLA-Net, a state-of-the-art neural network architecture, for the 3D segmentation of large-scale point cloud data in urban areas. The study focuses on three major Chinese cities, namely Chengdu, Jiaoda, and Shenzhen, leveraging their unique characteristics to enhance segmentation performance. To address the limited availability of labeled data for these specific urban areas, we employed transfer learning techniques. We transferred the learned weights from the Sensat Urban and Toronto 3D datasets to initialize our RandLA-Net model. Additionally, we performed class remapping to adapt the model to the target urban areas, ensuring accurate segmentation results. The experimental results demonstrate the effectiveness of the proposed approach achieving over 80\% F1 score for each areas in 3D point cloud segmentation. The transfer learning strategy proves to be crucial in overcoming data scarcity issues, providing a robust solution for urban point cloud analysis. The findings contribute to the advancement of point cloud segmentation methods, especially in the context of rapidly evolving Chinese urban areas.
Building Segmentation on Satellite Images and Performance of Post-Processing Methods
Dec 28, 2022



Researchers are doing intensive work on satellite images due to the information it contains with the development of computer vision algorithms and the ease of accessibility to satellite images. Building segmentation of satellite images can be used for many potential applications such as city, agricultural, and communication network planning. However, since no dataset exists for every region, the model trained in a region must gain generality. In this study, we trained several models in China and post-processing work was done on the best model selected among them. These models are evaluated in the Chicago region of the INRIA dataset. As can be seen from the results, although state-of-art results in this area have not been achieved, the results are promising. We aim to present our initial experimental results of a building segmentation from satellite images in this study.
Semi-Supervised Domain Adaptation for Semantic Segmentation of Roads from Satellite Images
Dec 26, 2022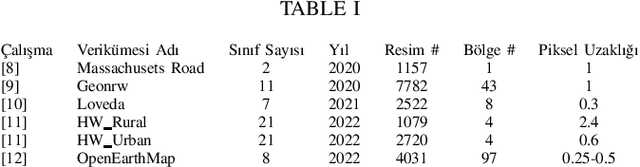
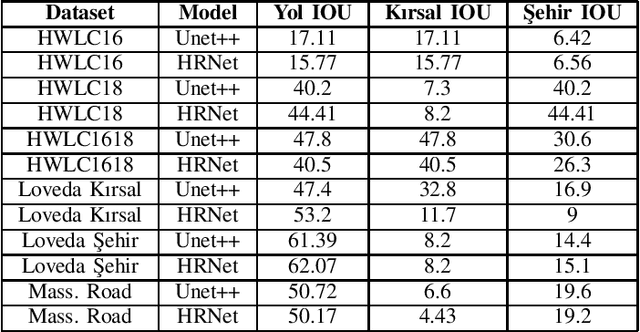
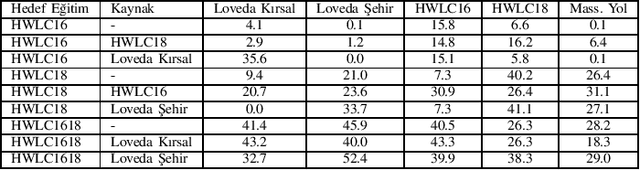
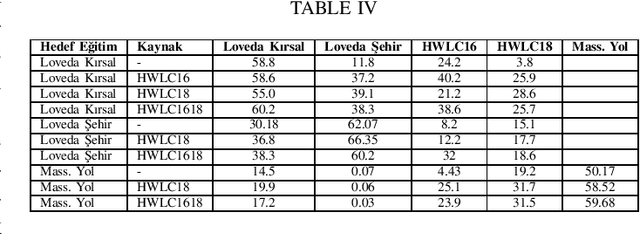
This paper presents the preliminary findings of a semi-supervised segmentation method for extracting roads from sattelite images. Artificial Neural Networks and image segmentation methods are among the most successful methods for extracting road data from satellite images. However, these models require large amounts of training data from different regions to achieve high accuracy rates. In cases where this data needs to be of more quantity or quality, it is a standard method to train deep neural networks by transferring knowledge from annotated data obtained from different sources. This study proposes a method that performs path segmentation with semi-supervised learning methods. A semi-supervised field adaptation method based on pseudo-labeling and Minimum Class Confusion method has been proposed, and it has been observed to increase performance in targeted datasets.
Real Time Incremental Image Mosaicking Without Use of Any Camera Parameter
Dec 05, 2022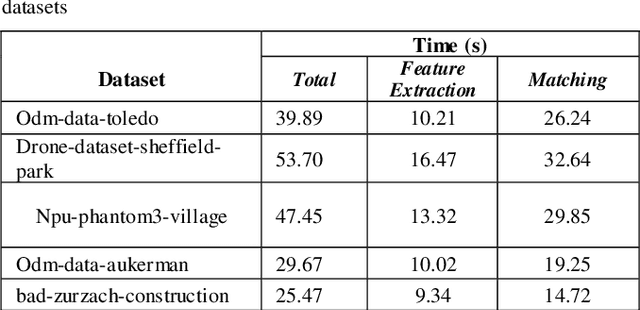

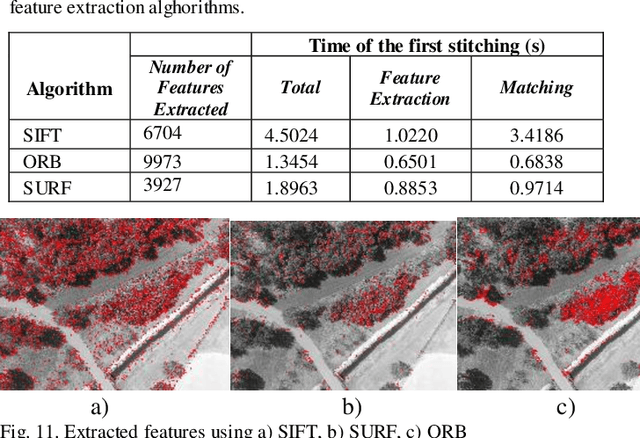

Over the past decade, there has been a significant increase in the use of Unmanned Aerial Vehicles (UAVs) to support a wide variety of missions, such as remote surveillance, vehicle tracking, and object detection. For problems involving processing of areas larger than a single image, the mosaicking of UAV imagery is a necessary step. Real-time image mosaicking is used for missions that requires fast response like search and rescue missions. It typically requires information from additional sensors, such as Global Position System (GPS) and Inertial Measurement Unit (IMU), to facilitate direct orientation, or 3D reconstruction approaches to recover the camera poses. This paper proposes a UAV-based system for real-time creation of incremental mosaics which does not require either direct or indirect camera parameters such as orientation information. Inspired by previous approaches, in the mosaicking process, feature extraction from images, matching of similar key points between images, finding homography matrix to warp and align images, and blending images to obtain mosaics better looking, plays important roles in the achievement of the high quality result. Edge detection is used in the blending step as a novel approach. Experimental results show that real-time incremental image mosaicking process can be completed satisfactorily and without need for any additional camera parameters.