 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Self-training for Unsupervised Domain Adaptation via Structural Constraints
Apr 29, 2023



Self-training based on pseudo-labels has emerged as a dominant approach for addressing conditional distribution shifts in unsupervised domain adaptation (UDA) for semantic segmentation problems. A notable drawback, however, is that this family of approaches is susceptible to erroneous pseudo labels that arise from confirmation biases in the source domain and that manifest as nuisance factors in the target domain. A possible source for this mismatch is the reliance on only photometric cues provided by RGB image inputs, which may ultimately lead to sub-optimal adaptation. To mitigate the effect of mismatched pseudo-labels, we propose to incorporate structural cues from auxiliary modalities, such as depth, to regularise conventional self-training objectives. Specifically, we introduce a contrastive pixel-level objectness constraint that pulls the pixel representations within a region of an object instance closer, while pushing those from different object categories apart. To obtain object regions consistent with the true underlying object, we extract information from both depth maps and RGB-images in the form of multimodal clustering. Crucially, the objectness constraint is agnostic to the ground-truth semantic labels and, hence, appropriate for unsupervised domain adaptation. In this work, we show that our regularizer significantly improves top performing self-training methods (by up to $2$ points) in various UDA benchmarks for semantic segmentation. We include all code in the supplementary.
Learning Expressive Prompting With Residuals for Vision Transformers
Mar 27, 2023Prompt learning is an efficient approach to adapt transformers by inserting learnable set of parameters into the input and intermediate representations of a pre-trained model. In this work, we present Expressive Prompts with Residuals (EXPRES) which modifies the prompt learning paradigm specifically for effective adaptation of vision transformers (ViT). Out method constructs downstream representations via learnable ``output'' tokens, that are akin to the learned class tokens of the ViT. Further for better steering of the downstream representation processed by the frozen transformer, we introduce residual learnable tokens that are added to the output of various computations. We apply EXPRES for image classification, few shot learning, and semantic segmentation, and show our method is capable of achieving state of the art prompt tuning on 3/3 categories of the VTAB benchmark. In addition to strong performance, we observe that our approach is an order of magnitude more prompt efficient than existing visual prompting baselines. We analytically show the computational benefits of our approach over weight space adaptation techniques like finetuning. Lastly we systematically corroborate the architectural design of our method via a series of ablation experiments.
On the Importance of Distractors for Few-Shot Classification
Sep 20, 2021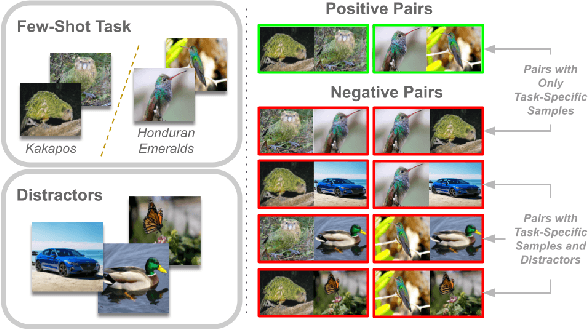

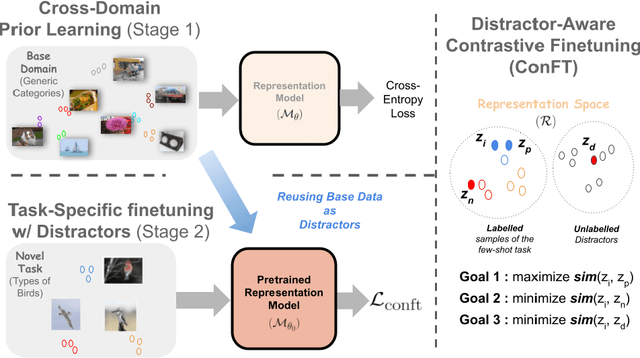
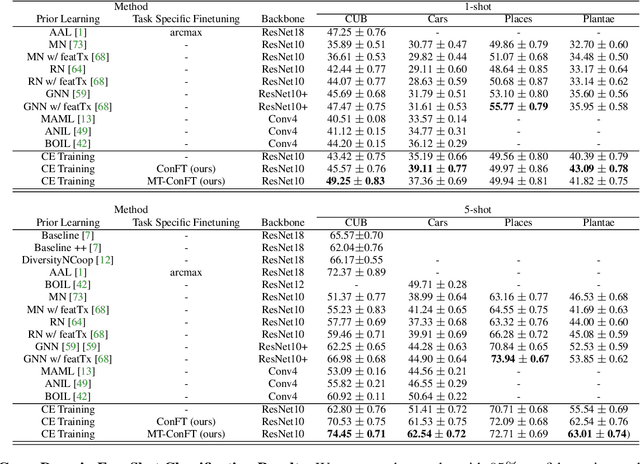
Few-shot classification aims at classifying categories of a novel task by learning from just a few (typically, 1 to 5) labelled examples. An effective approach to few-shot classification involves a prior model trained on a large-sample base domain, which is then finetuned over the novel few-shot task to yield generalizable representations. However, task-specific finetuning is prone to overfitting due to the lack of enough training examples. To alleviate this issue, we propose a new finetuning approach based on contrastive learning that reuses unlabelled examples from the base domain in the form of distractors. Unlike the nature of unlabelled data used in prior works, distractors belong to classes that do not overlap with the novel categories. We demonstrate for the first time that inclusion of such distractors can significantly boost few-shot generalization. Our technical novelty includes a stochastic pairing of examples sharing the same category in the few-shot task and a weighting term that controls the relative influence of task-specific negatives and distractors. An important aspect of our finetuning objective is that it is agnostic to distractor labels and hence applicable to various base domain settings. Compared to state-of-the-art approaches, our method shows accuracy gains of up to $12\%$ in cross-domain and up to $5\%$ in unsupervised prior-learning settings.