 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Self-training for Unsupervised Domain Adaptation via Structural Constraints
Apr 29, 2023



Self-training based on pseudo-labels has emerged as a dominant approach for addressing conditional distribution shifts in unsupervised domain adaptation (UDA) for semantic segmentation problems. A notable drawback, however, is that this family of approaches is susceptible to erroneous pseudo labels that arise from confirmation biases in the source domain and that manifest as nuisance factors in the target domain. A possible source for this mismatch is the reliance on only photometric cues provided by RGB image inputs, which may ultimately lead to sub-optimal adaptation. To mitigate the effect of mismatched pseudo-labels, we propose to incorporate structural cues from auxiliary modalities, such as depth, to regularise conventional self-training objectives. Specifically, we introduce a contrastive pixel-level objectness constraint that pulls the pixel representations within a region of an object instance closer, while pushing those from different object categories apart. To obtain object regions consistent with the true underlying object, we extract information from both depth maps and RGB-images in the form of multimodal clustering. Crucially, the objectness constraint is agnostic to the ground-truth semantic labels and, hence, appropriate for unsupervised domain adaptation. In this work, we show that our regularizer significantly improves top performing self-training methods (by up to $2$ points) in various UDA benchmarks for semantic segmentation. We include all code in the supplementary.
NIF: A Framework for Quantifying Neural Information Flow in Deep Networks
Jan 20, 2019

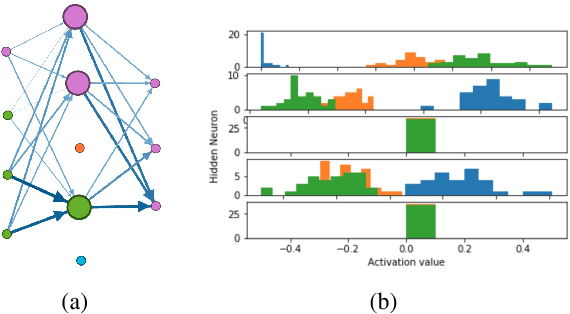
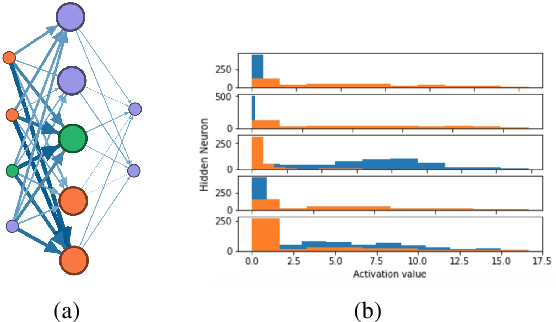
In this paper, we present a new approach to interpreting deep learning models. More precisely, by coupling mutual information with network science, we explore how information flows through feed forward networks. We show that efficiently approximating mutual information via the dual representation of Kullback-Leibler divergence allows us to create an information measure that quantifies how much information flows between any two neurons of a deep learning model. To that end, we propose NIF, Neural Information Flow, a new metric for codifying information flow which exposes the internals of a deep learning model while providing feature attributions.