 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAM: Semi-Supervised Learning with Localized Domain Adaptation and Iterative Matching
Paper and Code
Oct 13, 2020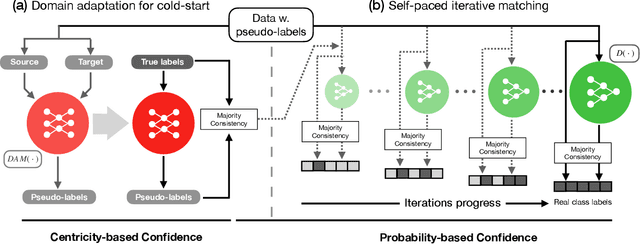
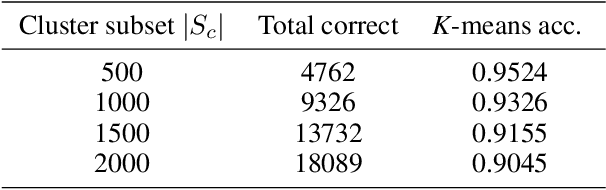
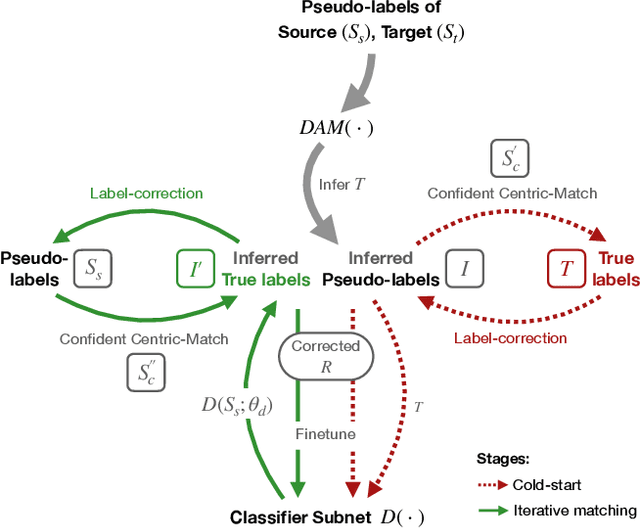
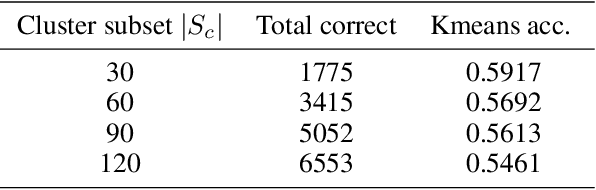
Although data is abundant, data labeling is expensive. Semi-supervised learning methods combine a few labeled samples with a large corpus of unlabeled data to effectively train models. This paper introduces our proposed method LiDAM, a semi-supervised learning approach rooted in both domain adaptation and self-paced learning. LiDAM first performs localized domain shifts to extract better domain-invariant features for the model that results in more accurate clusters and pseudo-labels. These pseudo-labels are then aligned with real class labels in a self-paced fashion using a novel iterative matching technique that is based on majority consistency over high-confidence predictions. Simultaneously, a final classifier is trained to predict ground-truth labels until convergence. LiDAM achieves state-of-the-art performance on the CIFAR-100 dataset, outperforming FixMatch (73.50% vs. 71.82%) when using 2500 labels.