 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than Just Attention: Learning Cross-Modal Attentions with Contrastive Constraints
Paper and Code
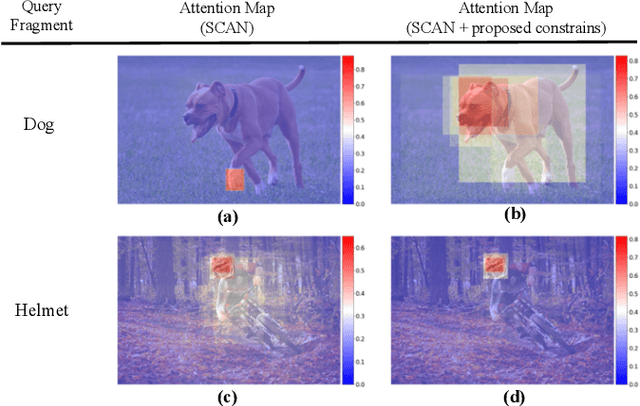
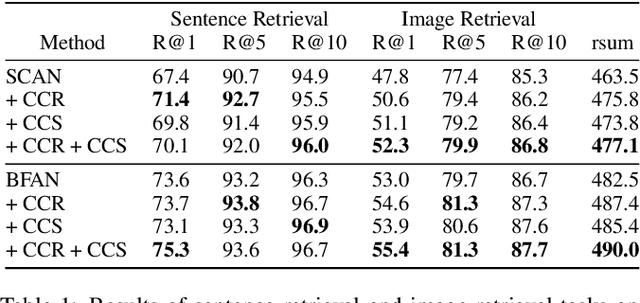
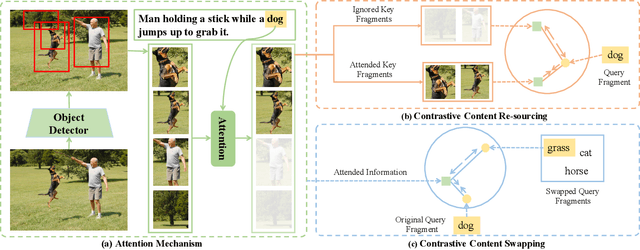
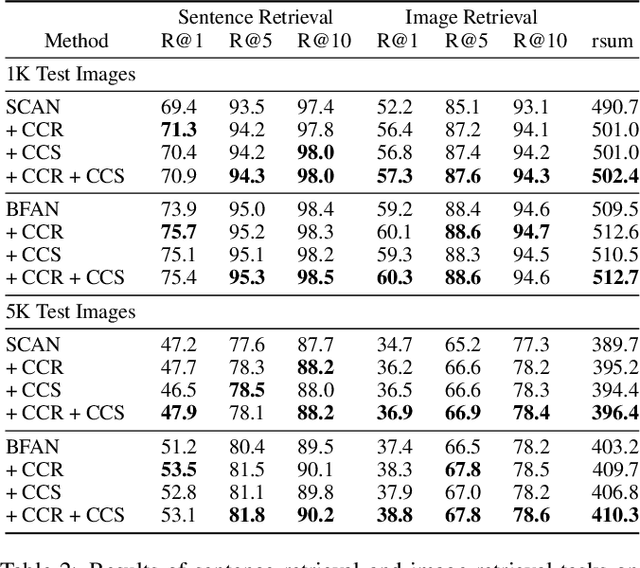
Attention mechanisms have been widely applied to cross-modal tasks such as image captioning and information retrieval, and have achieved remarkable improvements due to its capability to learn fine-grained relevance across different modalities. However, existing attention models could be sub-optimal and lack preciseness because there is no direct supervision involved during training. In this work, we propose Contrastive Content Re-sourcing (CCR) and Contrastive Content Swapping (CCS) constraints to address such limitation. These constraints supervise the training of attention models in a contrastive learning manner without requiring explicit attention annotations. Additionally, we introduce three metrics, namely Attention Precision, Recall and F1-Score, to quantitatively evaluate the attention quality. We evaluate the proposed constraints with cross-modal retrieval (image-text matching) task. The experiments on both Flickr30k and MS-COCO datasets demonstrate that integrating these attention constraints into two state-of-the-art attention-based models improves the model performance in terms of both retrieval accuracy and attention metrics.