 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLagNetViP: A Lagrangian Neural Network for Video Prediction
Paper and Code
Oct 24, 2020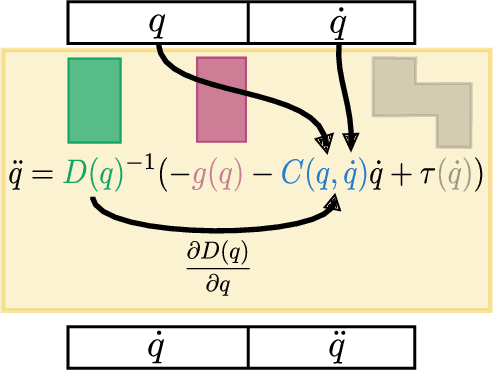



The dominant paradigms for video prediction rely on opaque transition models where neither the equations of motion nor the underlying physical quantities of the system are easily inferred. The equations of motion, as defined by Newton's second law, describe the time evolution of a physical system state and can therefore be applied toward the determination of future system states. In this paper, we introduce a video prediction model where the equations of motion are explicitly constructed from learned representations of the underlying physical quantities. To achieve this, we simultaneously learn a low-dimensional state representation and system Lagrangian. The kinetic and potential energy terms of the Lagrangian are distinctly modelled and the low-dimensional equations of motion are explicitly constructed using the Euler-Lagrange equations. We demonstrate the efficacy of this approach for video prediction on image sequences rendered in modified OpenAI gym Pendulum-v0 and Acrobot environments.