 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAN: Multi-Action Networks Learning
Paper and Code
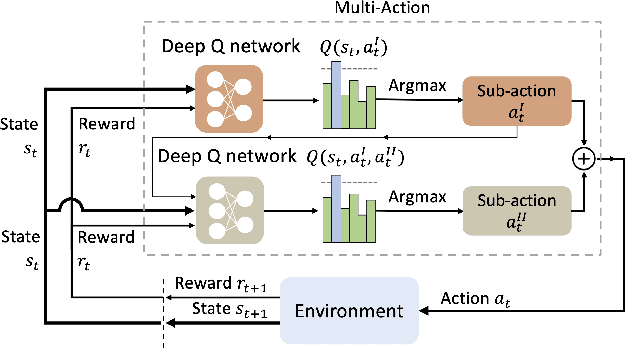

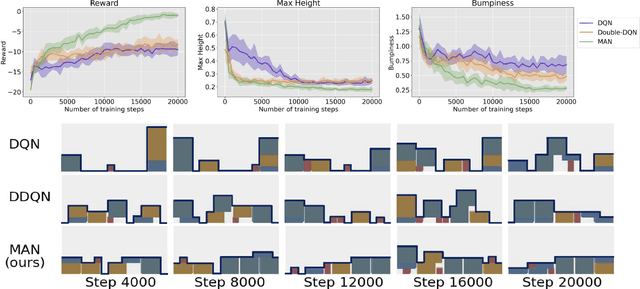

Learning control policies with large action spaces is a challenging problem in the field of reinforcement learning due to present inefficiencies in exploration. In this work, we introduce a Deep Reinforcement Learning (DRL) algorithm call Multi-Action Networks (MAN) Learning that addresses the challenge of large discrete action spaces. We propose separating the action space into two components, creating a Value Neural Network for each sub-action. Then, MAN uses temporal-difference learning to train the networks synchronously, which is simpler than training a single network with a large action output directly. To evaluate the proposed method, we test MAN on a block stacking task, and then extend MAN to handle 12 games from the Atari Arcade Learning environment with 18 action spaces. Our results indicate that MAN learns faster than both Deep Q-Learning and Double Deep Q-Learning, implying our method is a better performing synchronous temporal difference algorithm than those currently available for large action spaces.