 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinchBot: Long-Horizon Deformable Manipulation with Guided Diffusion Policy
Jul 23, 2025



Pottery creation is a complicated art form that requires dexterous, precise and delicate actions to slowly morph a block of clay to a meaningful, and often useful 3D goal shape. In this work, we aim to create a robotic system that can create simple pottery goals with only pinch-based actions. This pinch pottery task allows us to explore the challenges of a highly multi-modal and long-horizon deformable manipulation task. To this end, we present PinchBot, a goal-conditioned diffusion policy model that when combined with pre-trained 3D point cloud embeddings, task progress prediction and collision-constrained action projection, is able to successfully create a variety of simple pottery goals. For experimental videos and access to the demonstration dataset, please visit our project website: https://sites.google.com/andrew.cmu.edu/pinchbot/home.
RT-cache: Efficient Robot Trajectory Retrieval System
May 14, 2025



This paper introduces RT-cache, a novel trajectorymemory pipeline that accelerates real-world robot inference by leveraging big-data retrieval and learning from experience. While modern Vision-Language-Action (VLA) models can handle diverse robotic tasks, they often incur high per-step inference costs, resulting in significant latency, sometimes minutes per task. In contrast, RT-cache stores a large-scale Memory of previously successful robot trajectories and retrieves relevant multistep motion snippets, drastically reducing inference overhead. By integrating a Memory Builder with a Trajectory Retrieval, we develop an efficient retrieval process that remains tractable even for extremely large datasets. RT-cache flexibly accumulates real-world experiences and replays them whenever the current scene matches past states, adapting quickly to new or unseen environments with only a few additional samples. Experiments on the Open-X Embodiment Dataset and other real-world data demonstrate that RT-cache completes tasks both faster and more successfully than a baseline lacking retrieval, suggesting a practical, data-driven solution for real-time manipulation.
Planning and Reasoning with 3D Deformable Objects for Hierarchical Text-to-3D Robotic Shaping
Dec 02, 2024



Deformable object manipulation remains a key challenge in developing autonomous robotic systems that can be successfully deployed in real-world scenarios. In this work, we explore the challenges of deformable object manipulation through the task of sculpting clay into 3D shapes. We propose the first coarse-to-fine autonomous sculpting system in which the sculpting agent first selects how many and where to place discrete chunks of clay into the workspace to create a coarse shape, and then iteratively refines the shape with sequences of deformation actions. We leverage large language models for sub-goal generation, and train a point cloud region-based action model to predict robot actions from the desired point cloud sub-goals. Additionally, our method is the first autonomous sculpting system that is a real-world text-to-3D shaping pipeline without any explicit 3D goals or sub-goals provided to the system. We demonstrate our method is able to successfully create a set of simple shapes solely from text-based prompting. Furthermore, we explore rigorously how to best quantify success for the text-to-3D sculpting task, and compare existing text-image and text-point cloud similarity metrics to human evaluations for this task. For experimental videos, human evaluation details, and full prompts, please see our project website: https://sites.google.com/andrew.cmu.edu/hierarchicalsculpting
PLATO: Planning with LLMs and Affordances for Tool Manipulation
Sep 17, 2024



As robotic systems become increasingly integrated into complex real-world environments, there is a growing need for approaches that enable robots to understand and act upon natural language instructions without relying on extensive pre-programmed knowledge of their surroundings. This paper presents PLATO, an innovative system that addresses this challenge by leveraging specialized large language model agents to process natural language inputs, understand the environment, predict tool affordances, and generate executable actions for robotic systems. Unlike traditional systems that depend on hard-coded environmental information, PLATO employs a modular architecture of specialized agents to operate without any initial knowledge of the environment. These agents identify objects and their locations within the scene, generate a comprehensive high-level plan, translate this plan into a series of low-level actions, and verify the completion of each step. The system is particularly tested on challenging tool-use tasks, which involve handling diverse objects and require long-horizon planning. PLATO's design allows it to adapt to dynamic and unstructured settings, significantly enhancing its flexibility and robustness. By evaluating the system across various complex scenarios, we demonstrate its capability to tackle a diverse range of tasks and offer a novel solution to integrate LLMs with robotic platforms, advancing the state-of-the-art in autonomous robotic task execution. For videos and prompt details, please see our project website: https://sites.google.com/andrew.cmu.edu/plato
LLM-Craft: Robotic Crafting of Elasto-Plastic Objects with Large Language Models
Jun 12, 2024



When humans create sculptures, we are able to reason about how geometrically we need to alter the clay state to reach our target goal. We are not computing point-wise similarity metrics, or reasoning about low-level positioning of our tools, but instead determining the higher-level changes that need to be made. In this work, we propose LLM-Craft, a novel pipeline that leverages large language models (LLMs) to iteratively reason about and generate deformation-based crafting action sequences. We simplify and couple the state and action representations to further encourage shape-based reasoning. To the best of our knowledge, LLM-Craft is the first system successfully leveraging LLMs for complex deformable object interactions. Through our experiments, we demonstrate that with the LLM-Craft framework, LLMs are able to successfully reason about the deformation behavior of elasto-plastic objects. Furthermore, we find that LLM-Craft is able to successfully create a set of simple letter shapes. Finally, we explore extending the framework to reaching more ambiguous semantic goals, such as "thinner" or "bumpy". For videos please see our website: https://sites.google.com/andrew.cmu.edu/llmcraft.
SculptDiff: Learning Robotic Clay Sculpting from Humans with Goal Conditioned Diffusion Policy
Mar 15, 2024Manipulating deformable objects remains a challenge within robotics due to the difficulties of state estimation, long-horizon planning, and predicting how the object will deform given an interaction. These challenges are the most pronounced with 3D deformable objects. We propose SculptDiff, a goal-conditioned diffusion-based imitation learning framework that works with point cloud state observations to directly learn clay sculpting policies for a variety of target shapes. To the best of our knowledge this is the first real-world method that successfully learns manipulation policies for 3D deformable objects. For sculpting videos and access to our dataset and hardware CAD models, see the project website: https://sites.google.com/andrew.cmu.edu/imitation-sculpting/home
Pour me a drink: Robotic Precision Pouring Carbonated Beverages into Transparent Containers
Sep 19, 2023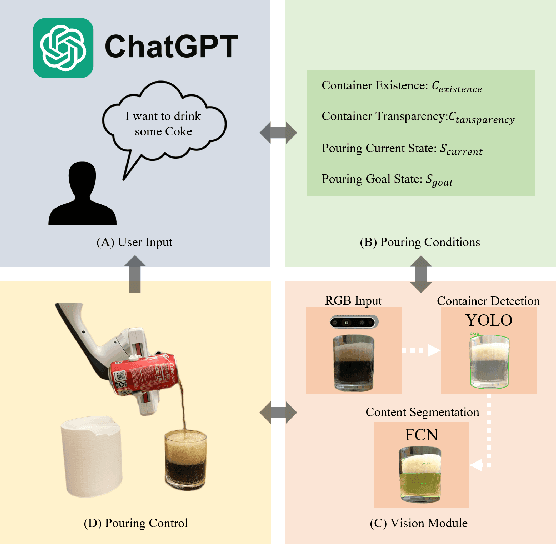



With the growing emphasis on the development and integration of service robots within household environments, we will need to endow robots with the ability to reliably pour a variety of liquids. However, liquid handling and pouring is a challenging task due to the complex dynamics and varying properties of different liquids, the exacting precision required to prevent spills and ensure accurate pouring, and the necessity for robots to adapt seamlessly to a multitude of containers in real-world scenarios. In response to these challenges, we propose a novel autonomous robotics pipeline that empowers robots to execute precision pouring tasks, encompassing both carbonated and non-carbonated liquids, as well as opaque and transparent liquids, into a variety of transparent containers. Our proposed approach maximizes the potential of RGB input alone, achieving zero-shot capability by harnessing existing pre-trained vision segmentation models. This eliminates the need for additional data collection, manual image annotations, or extensive training. Furthermore, our work integrates ChatGPT, facilitating seamless interaction between individuals without prior expertise in robotics and our pouring pipeline, this integration enables users to effortlessly request and execute pouring actions. Our experiments demonstrate the pipeline's capability to successfully pour a diverse range of carbonated and non-carbonated beverages into containers of varying sizes, relying solely on visual input.
SculptBot: Pre-Trained Models for 3D Deformable Object Manipulation
Sep 15, 2023Deformable object manipulation presents a unique set of challenges in robotic manipulation by exhibiting high degrees of freedom and severe self-occlusion. State representation for materials that exhibit plastic behavior, like modeling clay or bread dough, is also difficult because they permanently deform under stress and are constantly changing shape. In this work, we investigate each of these challenges using the task of robotic sculpting with a parallel gripper. We propose a system that uses point clouds as the state representation and leverages pre-trained point cloud reconstruction Transformer to learn a latent dynamics model to predict material deformations given a grasp action. We design a novel action sampling algorithm that reasons about geometrical differences between point clouds to further improve the efficiency of model-based planners. All data and experiments are conducted entirely in the real world. Our experiments show the proposed system is able to successfully capture the dynamics of clay, and is able to create a variety of simple shapes.
Fluid Property Prediction Leveraging AI and Robotics
Aug 04, 2023Inferring liquid properties from vision is a challenging task due to the complex nature of fluids, both in behavior and detection. Nevertheless, the ability to infer their properties directly from visual information is highly valuable for autonomous fluid handling systems, as cameras are readily available. Moreover, predicting fluid properties purely from vision can accelerate the process of fluid characterization saving considerable time and effort in various experimental environments. In this work, we present a purely vision-based approach to estimate viscosity, leveraging the fact that the behavior of the fluid oscillations is directly related to the viscosity. Specifically, we utilize a 3D convolutional autoencoder to learn latent representations of different fluid-oscillating patterns present in videos. We leverage this latent representation to visually infer the category of fluid or the dynamics viscosity of fluid from video.
RoboChop: Autonomous Framework for Fruit and Vegetable Chopping Leveraging Foundational Models
Jul 24, 2023
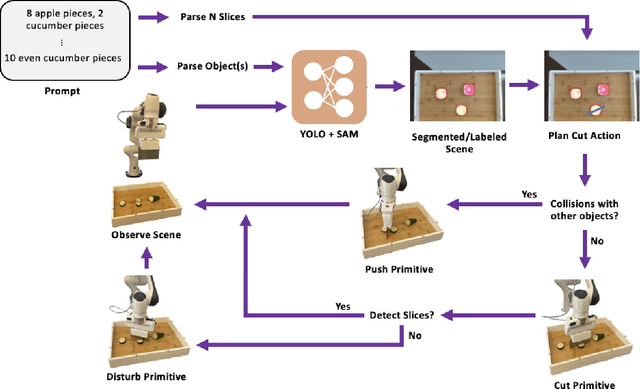
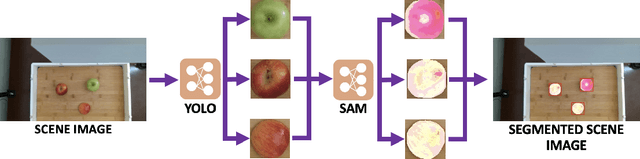
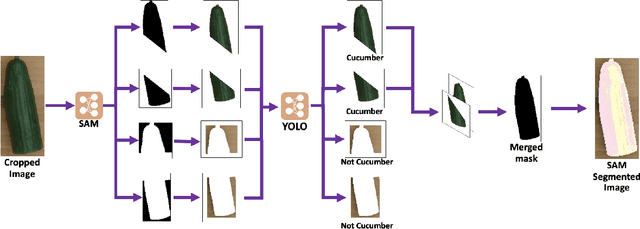
With the goal of developing fully autonomous cooking robots, developing robust systems that can chop a wide variety of objects is important. Existing approaches focus primarily on the low-level dynamics of the cutting action, which overlooks some of the practical real-world challenges of implementing autonomous cutting systems. In this work we propose an autonomous framework to sequence together action primitives for the purpose of chopping fruits and vegetables on a cluttered cutting board. We present a novel technique to leverage vision foundational models SAM and YOLO to accurately detect, segment, and track fruits and vegetables as they visually change through the sequences of chops, finetuning YOLO on a novel dataset of whole and chopped fruits and vegetables. In our experiments, we demonstrate that our simple pipeline is able to reliably chop a variety of fruits and vegetables ranging in size, appearance, and texture, meeting a variety of chopping specifications, including fruit type, number of slices, and types of slices.