 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePour me a drink: Robotic Precision Pouring Carbonated Beverages into Transparent Containers
Sep 19, 2023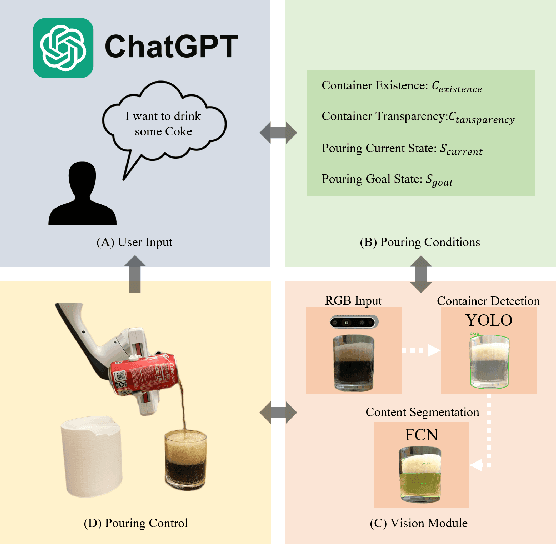



With the growing emphasis on the development and integration of service robots within household environments, we will need to endow robots with the ability to reliably pour a variety of liquids. However, liquid handling and pouring is a challenging task due to the complex dynamics and varying properties of different liquids, the exacting precision required to prevent spills and ensure accurate pouring, and the necessity for robots to adapt seamlessly to a multitude of containers in real-world scenarios. In response to these challenges, we propose a novel autonomous robotics pipeline that empowers robots to execute precision pouring tasks, encompassing both carbonated and non-carbonated liquids, as well as opaque and transparent liquids, into a variety of transparent containers. Our proposed approach maximizes the potential of RGB input alone, achieving zero-shot capability by harnessing existing pre-trained vision segmentation models. This eliminates the need for additional data collection, manual image annotations, or extensive training. Furthermore, our work integrates ChatGPT, facilitating seamless interaction between individuals without prior expertise in robotics and our pouring pipeline, this integration enables users to effortlessly request and execute pouring actions. Our experiments demonstrate the pipeline's capability to successfully pour a diverse range of carbonated and non-carbonated beverages into containers of varying sizes, relying solely on visual input.
MPMQA: Multimodal Question Answering on Product Manuals
Apr 19, 2023Visual contents, such as illustrations and images, play a big role in product manual understanding. Existing Product Manual Question Answering (PMQA) datasets tend to ignore visual contents and only retain textual parts. In this work, to emphasize the importance of multimodal contents, we propose a Multimodal Product Manual Question Answering (MPMQA) task. For each question, MPMQA requires the model not only to process multimodal contents but also to provide multimodal answers. To support MPMQA, a large-scale dataset PM209 is constructed with human annotations, which contains 209 product manuals from 27 well-known consumer electronic brands. Human annotations include 6 types of semantic regions for manual contents and 22,021 pairs of question and answer. Especially, each answer consists of a textual sentence and related visual regions from manuals. Taking into account the length of product manuals and the fact that a question is always related to a small number of pages, MPMQA can be naturally split into two subtasks: retrieving most related pages and then generating multimodal answers. We further propose a unified model that can perform these two subtasks all together and achieve comparable performance with multiple task-specific models. The PM209 dataset is available at https://github.com/AIM3-RUC/MPMQA.