 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Up Natural Language Understanding for Multi-Robots Through the Lens of Hierarchy
Aug 15, 2024



Long-horizon planning is hindered by challenges such as uncertainty accumulation, computational complexity, delayed rewards and incomplete information. This work proposes an approach to exploit the task hierarchy from human instructions to facilitate multi-robot planning. Using Large Language Models (LLMs), we propose a two-step approach to translate multi-sentence instructions into a structured language, Hierarchical Linear Temporal Logic (LTL), which serves as a formal representation for planning. Initially, LLMs transform the instructions into a hierarchical representation defined as Hierarchical Task Tree, capturing the logical and temporal relations among tasks. Following this, a domain-specific fine-tuning of LLM translates sub-tasks of each task into flat LTL formulas, aggregating them to form hierarchical LTL specifications. These specifications are then leveraged for planning using off-the-shelf planners. Our framework not only bridges the gap between instructions and algorithmic planning but also showcases the potential of LLMs in harnessing hierarchical reasoning to automate multi-robot task planning. Through evaluations in both simulation and real-world experiments involving human participants, we demonstrate that our method can handle more complex instructions compared to existing methods. The results indicate that our approach achieves higher success rates and lower costs in multi-robot task allocation and plan generation. Demos videos are available at https://youtu.be/7WOrDKxIMIs .
Pour me a drink: Robotic Precision Pouring Carbonated Beverages into Transparent Containers
Sep 19, 2023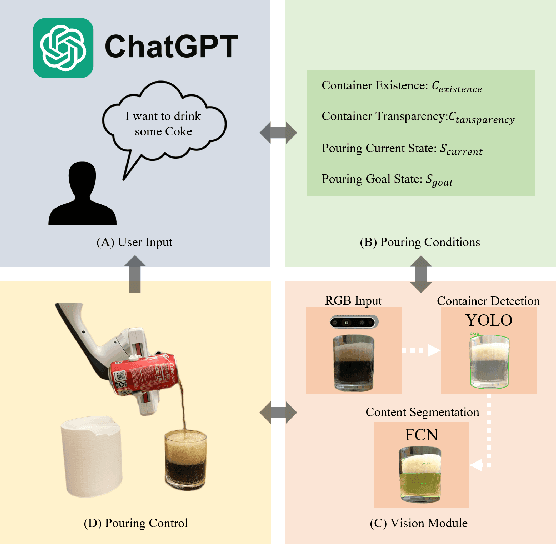



With the growing emphasis on the development and integration of service robots within household environments, we will need to endow robots with the ability to reliably pour a variety of liquids. However, liquid handling and pouring is a challenging task due to the complex dynamics and varying properties of different liquids, the exacting precision required to prevent spills and ensure accurate pouring, and the necessity for robots to adapt seamlessly to a multitude of containers in real-world scenarios. In response to these challenges, we propose a novel autonomous robotics pipeline that empowers robots to execute precision pouring tasks, encompassing both carbonated and non-carbonated liquids, as well as opaque and transparent liquids, into a variety of transparent containers. Our proposed approach maximizes the potential of RGB input alone, achieving zero-shot capability by harnessing existing pre-trained vision segmentation models. This eliminates the need for additional data collection, manual image annotations, or extensive training. Furthermore, our work integrates ChatGPT, facilitating seamless interaction between individuals without prior expertise in robotics and our pouring pipeline, this integration enables users to effortlessly request and execute pouring actions. Our experiments demonstrate the pipeline's capability to successfully pour a diverse range of carbonated and non-carbonated beverages into containers of varying sizes, relying solely on visual input.