 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboChop: Autonomous Framework for Fruit and Vegetable Chopping Leveraging Foundational Models
Paper and Code
Jul 24, 2023
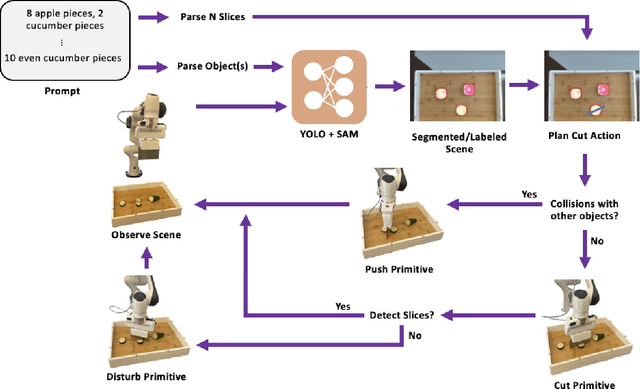
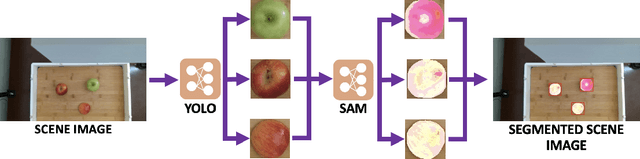
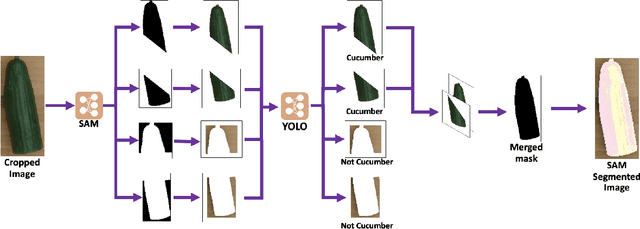
With the goal of developing fully autonomous cooking robots, developing robust systems that can chop a wide variety of objects is important. Existing approaches focus primarily on the low-level dynamics of the cutting action, which overlooks some of the practical real-world challenges of implementing autonomous cutting systems. In this work we propose an autonomous framework to sequence together action primitives for the purpose of chopping fruits and vegetables on a cluttered cutting board. We present a novel technique to leverage vision foundational models SAM and YOLO to accurately detect, segment, and track fruits and vegetables as they visually change through the sequences of chops, finetuning YOLO on a novel dataset of whole and chopped fruits and vegetables. In our experiments, we demonstrate that our simple pipeline is able to reliably chop a variety of fruits and vegetables ranging in size, appearance, and texture, meeting a variety of chopping specifications, including fruit type, number of slices, and types of slices.