 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Mat-Bench: Benchmarking Large Language Models for Materials Property Prediction
Oct 31, 2024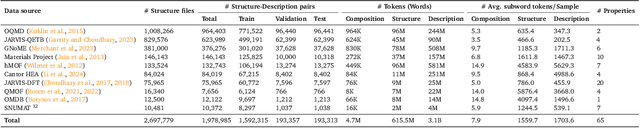
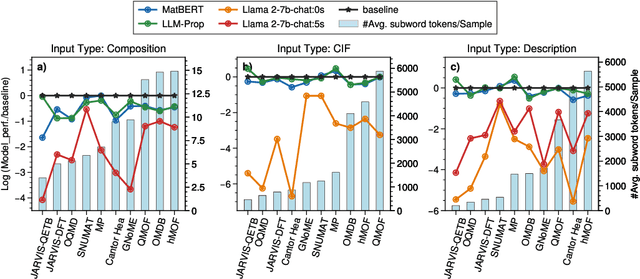

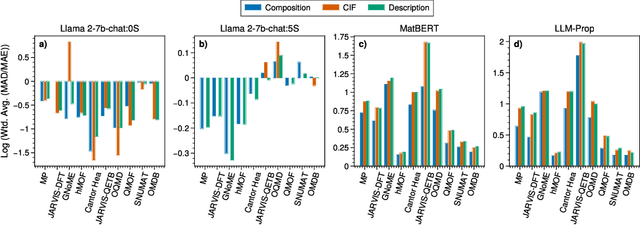
Large language models (LLMs) are increasingly being used in materials science. However, little attention has been given to benchmarking and standardized evaluation for LLM-based materials property prediction, which hinders progress. We present LLM4Mat-Bench, the largest benchmark to date for evaluating the performance of LLMs in predicting the properties of crystalline materials. LLM4Mat-Bench contains about 1.9M crystal structures in total, collected from 10 publicly available materials data sources, and 45 distinct properties. LLM4Mat-Bench features different input modalities: crystal composition, CIF, and crystal text description, with 4.7M, 615.5M, and 3.1B tokens in total for each modality, respectively. We use LLM4Mat-Bench to fine-tune models with different sizes, including LLM-Prop and MatBERT, and provide zero-shot and few-shot prompts to evaluate the property prediction capabilities of LLM-chat-like models, including Llama, Gemma, and Mistral. The results highlight the challenges of general-purpose LLMs in materials science and the need for task-specific predictive models and task-specific instruction-tuned LLMs in materials property prediction.
LLM-Prop: Predicting Physical And Electronic Properties Of Crystalline Solids From Their Text Descriptions
Oct 21, 2023



The prediction of crystal properties plays a crucial role in the crystal design process. Current methods for predicting crystal properties focus on modeling crystal structures using graph neural networks (GNNs). Although GNNs are powerful, accurately modeling the complex interactions between atoms and molecules within a crystal remains a challenge. Surprisingly, predicting crystal properties from crystal text descriptions is understudied, despite the rich information and expressiveness that text data offer. One of the main reasons is the lack of publicly available data for this task. In this paper, we develop and make public a benchmark dataset (called TextEdge) that contains text descriptions of crystal structures with their properties. We then propose LLM-Prop, a method that leverages the general-purpose learning capabilities of large language models (LLMs) to predict the physical and electronic properties of crystals from their text descriptions. LLM-Prop outperforms the current state-of-the-art GNN-based crystal property predictor by about 4% in predicting band gap, 3% in classifying whether the band gap is direct or indirect, and 66% in predicting unit cell volume. LLM-Prop also outperforms a finetuned MatBERT, a domain-specific pre-trained BERT model, despite having 3 times fewer parameters. Our empirical results may highlight the current inability of GNNs to capture information pertaining to space group symmetry and Wyckoff sites for accurate crystal property prediction.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022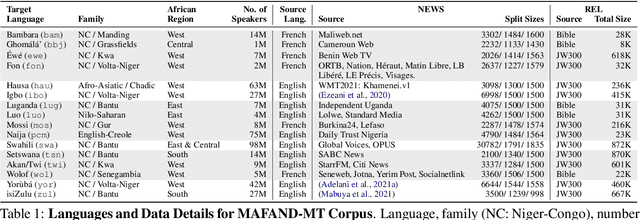
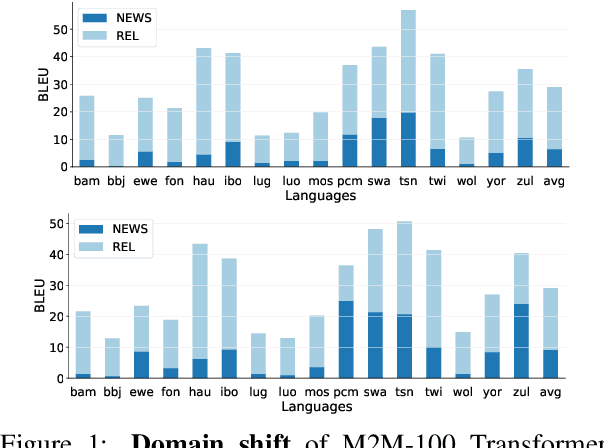

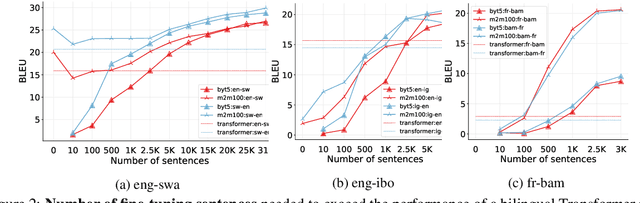
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
KinyaBERT: a Morphology-aware Kinyarwanda Language Model
Mar 17, 2022
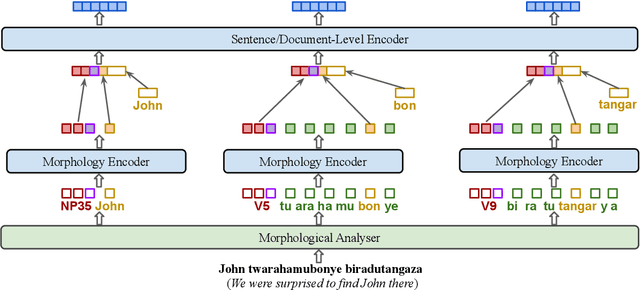
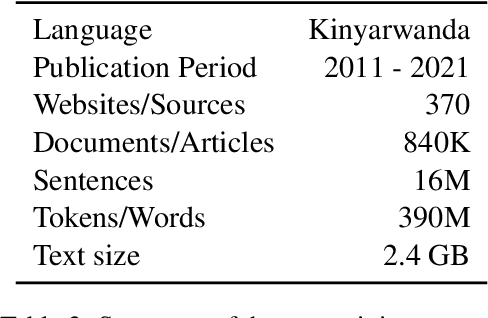
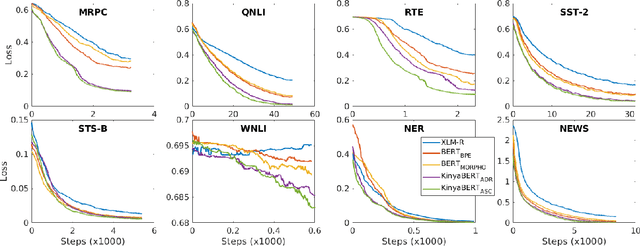
Pre-trained language models such as BERT have been successful at tackling many natural language processing tasks. However, the unsupervised sub-word tokenization methods commonly used in these models (e.g., byte-pair encoding - BPE) are sub-optimal at handling morphologically rich languages. Even given a morphological analyzer, naive sequencing of morphemes into a standard BERT architecture is inefficient at capturing morphological compositionality and expressing word-relative syntactic regularities. We address these challenges by proposing a simple yet effective two-tier BERT architecture that leverages a morphological analyzer and explicitly represents morphological compositionality. Despite the success of BERT, most of its evaluations have been conducted on high-resource languages, obscuring its applicability on low-resource languages. We evaluate our proposed method on the low-resource morphologically rich Kinyarwanda language, naming the proposed model architecture KinyaBERT. A robust set of experimental results reveal that KinyaBERT outperforms solid baselines by 2% in F1 score on a named entity recognition task and by 4.3% in average score of a machine-translated GLUE benchmark. KinyaBERT fine-tuning has better convergence and achieves more robust results on multiple tasks even in the presence of translation noise.