 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-resource neural machine translation with morphological modeling
Apr 03, 2024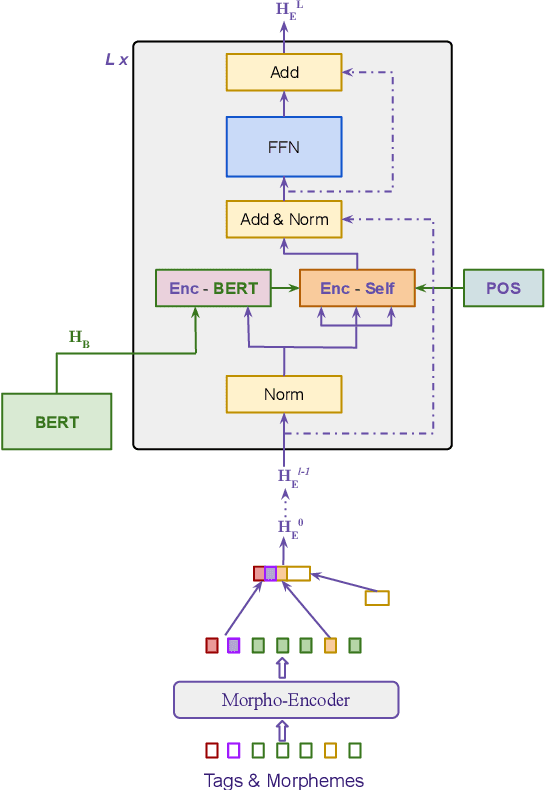

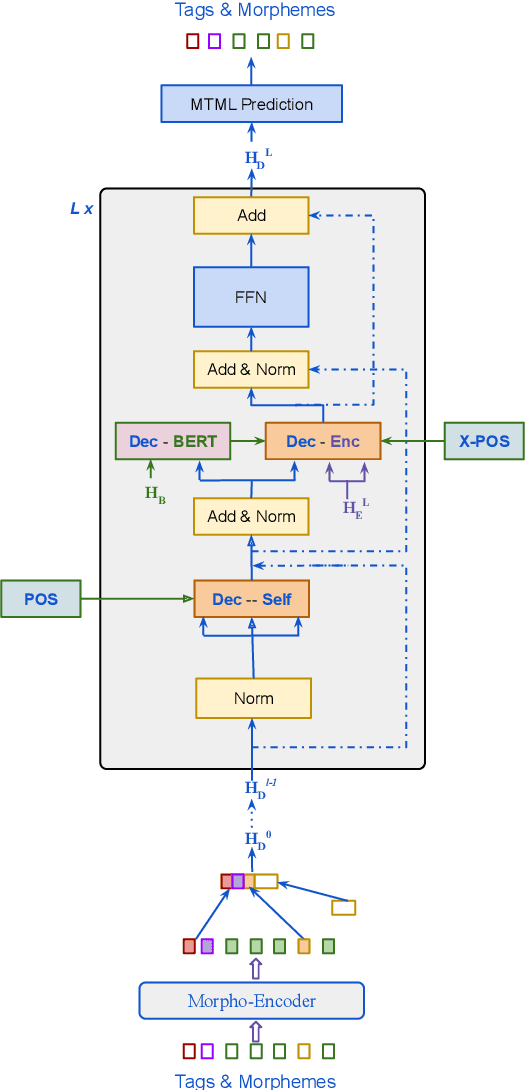
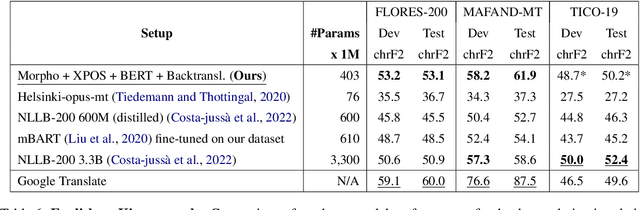
Morphological modeling in neural machine translation (NMT) is a promising approach to achieving open-vocabulary machine translation for morphologically-rich languages. However, existing methods such as sub-word tokenization and character-based models are limited to the surface forms of the words. In this work, we propose a framework-solution for modeling complex morphology in low-resource settings. A two-tier transformer architecture is chosen to encode morphological information at the inputs. At the target-side output, a multi-task multi-label training scheme coupled with a beam search-based decoder are found to improve machine translation performance. An attention augmentation scheme to the transformer model is proposed in a generic form to allow integration of pre-trained language models and also facilitate modeling of word order relationships between the source and target languages. Several data augmentation techniques are evaluated and shown to increase translation performance in low-resource settings. We evaluate our proposed solution on Kinyarwanda - English translation using public-domain parallel text. Our final models achieve competitive performance in relation to large multi-lingual models. We hope that our results will motivate more use of explicit morphological information and the proposed model and data augmentations in low-resource NMT.
KinSPEAK: Improving speech recognition for Kinyarwanda via semi-supervised learning methods
Aug 23, 2023



Despite recent availability of large transcribed Kinyarwanda speech data, achieving robust speech recognition for Kinyarwanda is still challenging. In this work, we show that using self-supervised pre-training, following a simple curriculum schedule during fine-tuning and using semi-supervised learning to leverage large unlabelled speech data significantly improve speech recognition performance for Kinyarwanda. Our approach focuses on using public domain data only. A new studio-quality speech dataset is collected from a public website, then used to train a clean baseline model. The clean baseline model is then used to rank examples from a more diverse and noisy public dataset, defining a simple curriculum training schedule. Finally, we apply semi-supervised learning to label and learn from large unlabelled data in four successive generations. Our final model achieves 3.2% word error rate (WER) on the new dataset and 15.9% WER on Mozilla Common Voice benchmark, which is state-of-the-art to the best of our knowledge. Our experiments also indicate that using syllabic rather than character-based tokenization results in better speech recognition performance for Kinyarwanda.
KINLP at SemEval-2023 Task 12: Kinyarwanda Tweet Sentiment Analysis
Apr 25, 2023
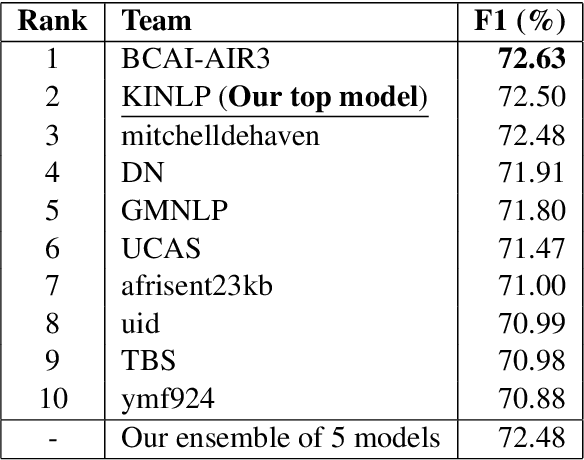

This paper describes the system entered by the author to the SemEval-2023 Task 12: Sentiment analysis for African languages. The system focuses on the Kinyarwanda language and uses a language-specific model. Kinyarwanda morphology is modeled in a two tier transformer architecture and the transformer model is pre-trained on a large text corpus using multi-task masked morphology prediction. The model is deployed on an experimental platform that allows users to experiment with the pre-trained language model fine-tuning without the need to write machine learning code. Our final submission to the shared task achieves second ranking out of 34 teams in the competition, achieving 72.50% weighted F1 score. Our analysis of the evaluation results highlights challenges in achieving high accuracy on the task and identifies areas for improvement.
KinyaBERT: a Morphology-aware Kinyarwanda Language Model
Mar 17, 2022
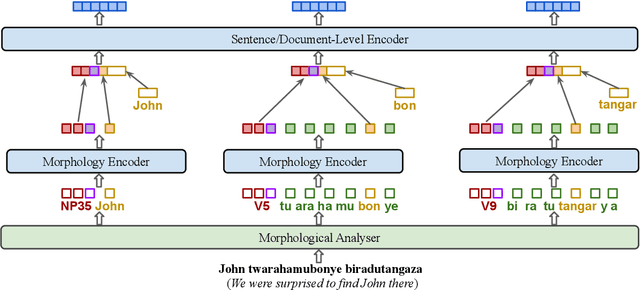
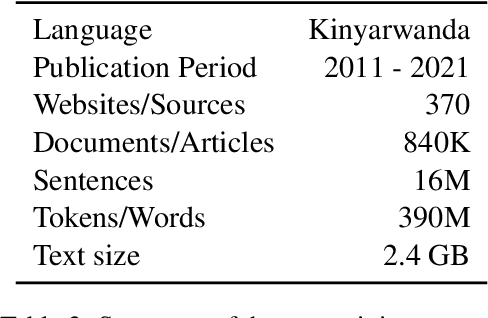
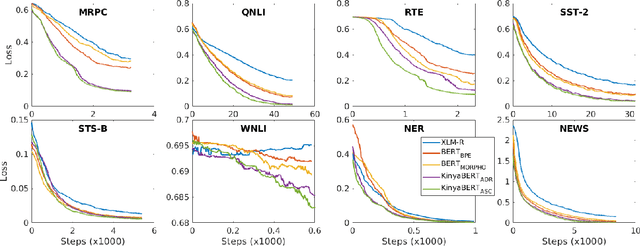
Pre-trained language models such as BERT have been successful at tackling many natural language processing tasks. However, the unsupervised sub-word tokenization methods commonly used in these models (e.g., byte-pair encoding - BPE) are sub-optimal at handling morphologically rich languages. Even given a morphological analyzer, naive sequencing of morphemes into a standard BERT architecture is inefficient at capturing morphological compositionality and expressing word-relative syntactic regularities. We address these challenges by proposing a simple yet effective two-tier BERT architecture that leverages a morphological analyzer and explicitly represents morphological compositionality. Despite the success of BERT, most of its evaluations have been conducted on high-resource languages, obscuring its applicability on low-resource languages. We evaluate our proposed method on the low-resource morphologically rich Kinyarwanda language, naming the proposed model architecture KinyaBERT. A robust set of experimental results reveal that KinyaBERT outperforms solid baselines by 2% in F1 score on a named entity recognition task and by 4.3% in average score of a machine-translated GLUE benchmark. KinyaBERT fine-tuning has better convergence and achieves more robust results on multiple tasks even in the presence of translation noise.
Morphological Disambiguation from Stemming Data
Nov 11, 2020
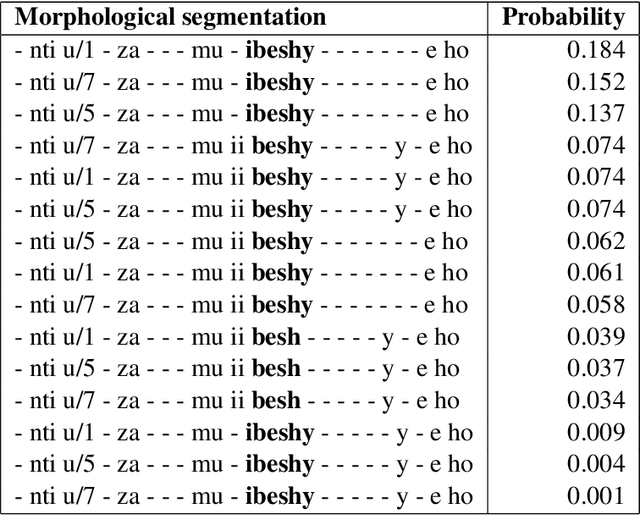

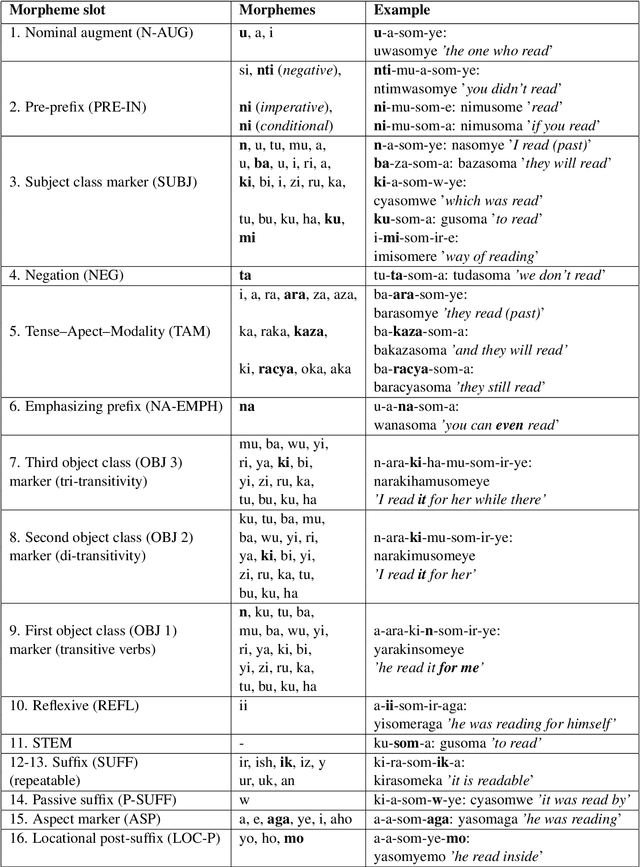
Morphological analysis and disambiguation is an important task and a crucial preprocessing step in natural language processing of morphologically rich languages. Kinyarwanda, a morphologically rich language, currently lacks tools for automated morphological analysis. While linguistically curated finite state tools can be easily developed for morphological analysis, the morphological richness of the language allows many ambiguous analyses to be produced, requiring effective disambiguation. In this paper, we propose learning to morphologically disambiguate Kinyarwanda verbal forms from a new stemming dataset collected through crowd-sourcing. Using feature engineering and a feed-forward neural network based classifier, we achieve about 89% non-contextualized disambiguation accuracy. Our experiments reveal that inflectional properties of stems and morpheme association rules are the most discriminative features for disambiguation.