 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Disambiguation from Stemming Data
Paper and Code
Nov 11, 2020
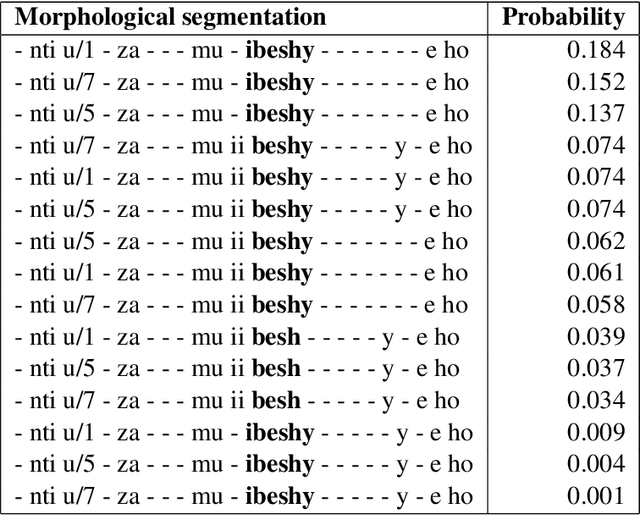

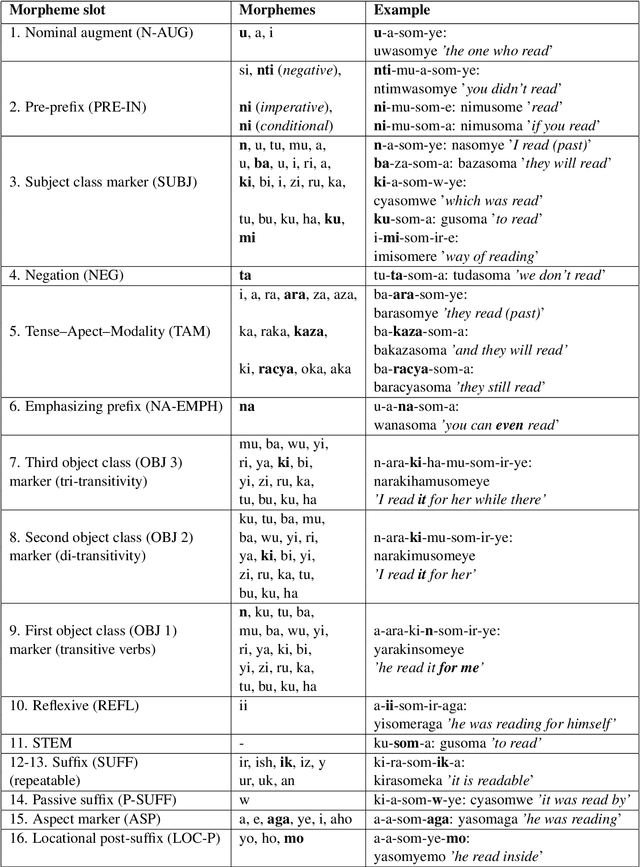
Morphological analysis and disambiguation is an important task and a crucial preprocessing step in natural language processing of morphologically rich languages. Kinyarwanda, a morphologically rich language, currently lacks tools for automated morphological analysis. While linguistically curated finite state tools can be easily developed for morphological analysis, the morphological richness of the language allows many ambiguous analyses to be produced, requiring effective disambiguation. In this paper, we propose learning to morphologically disambiguate Kinyarwanda verbal forms from a new stemming dataset collected through crowd-sourcing. Using feature engineering and a feed-forward neural network based classifier, we achieve about 89% non-contextualized disambiguation accuracy. Our experiments reveal that inflectional properties of stems and morpheme association rules are the most discriminative features for disambiguation.