 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Prosody in Spoken Question Answering
Paper and Code
Feb 08, 2025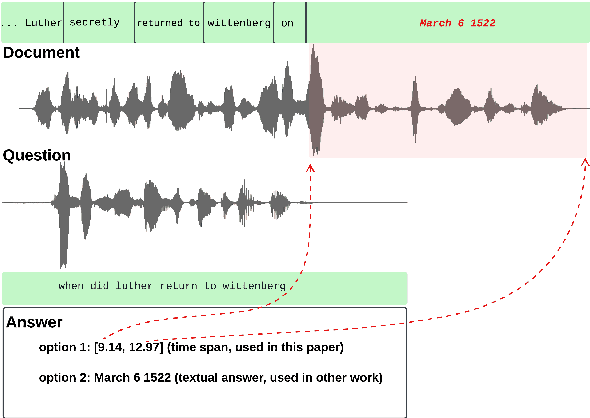
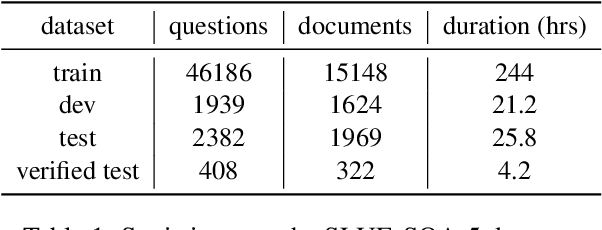
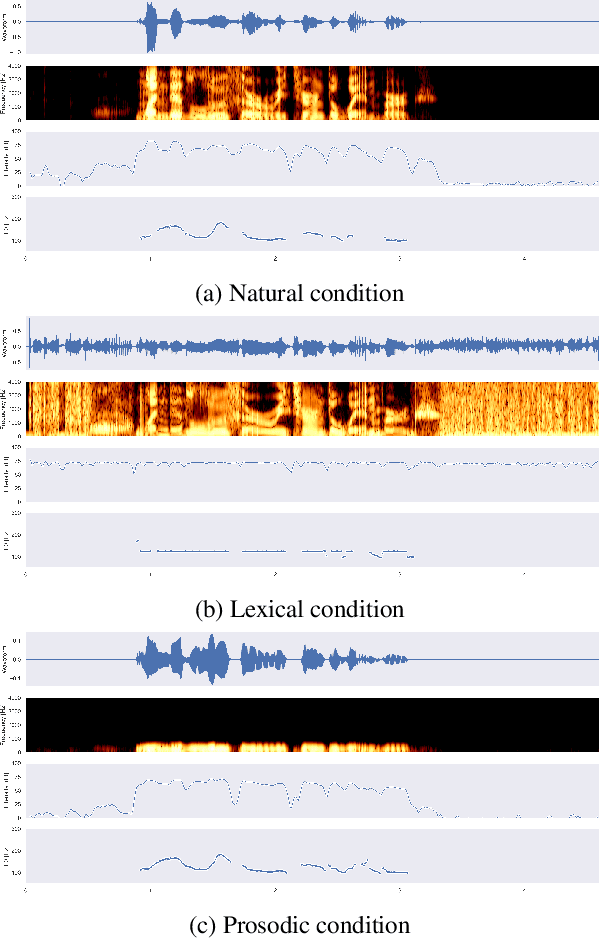
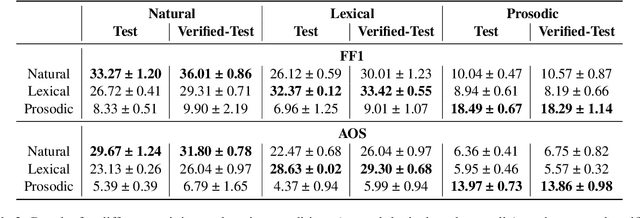
Spoken language understanding research to date has generally carried a heavy text perspective. Most datasets are derived from text, which is then subsequently synthesized into speech, and most models typically rely on automatic transcriptions of speech. This is to the detriment of prosody--additional information carried by the speech signal beyond the phonetics of the words themselves and difficult to recover from text alone. In this work, we investigate the role of prosody in Spoken Question Answering. By isolating prosodic and lexical information on the SLUE-SQA-5 dataset, which consists of natural speech, we demonstrate that models trained on prosodic information alone can perform reasonably well by utilizing prosodic cues. However, we find that when lexical information is available, models tend to predominantly rely on it. Our findings suggest that while prosodic cues provide valuable supplementary information, more effective integration methods are required to ensure prosody contributes more significantly alongside lexical features.