 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIREx: Augmenting Language Inference with Relevant Explanation
Paper and Code

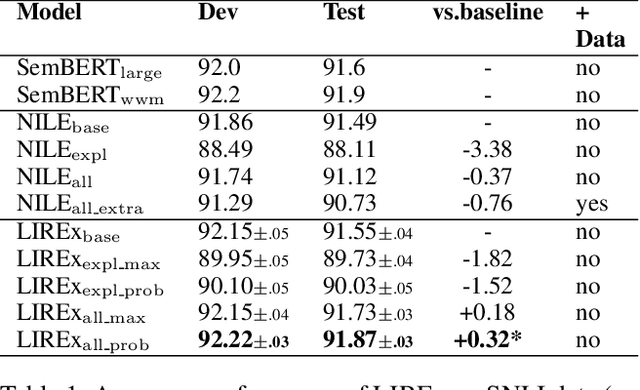
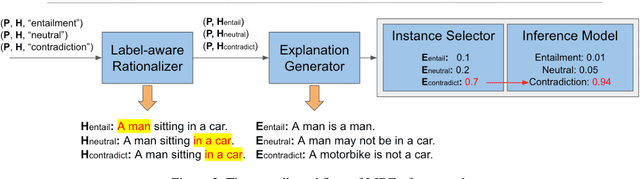
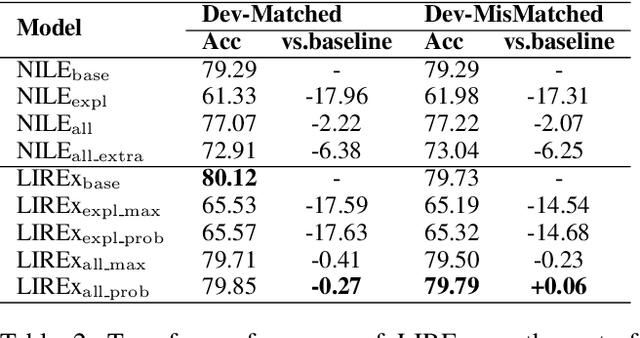
Natural language explanations (NLEs) are a special form of data annotation in which annotators identify rationales (most significant text tokens) when assigning labels to data instances, and write out explanations for the labels in natural language based on the rationales. NLEs have been shown to capture human reasoning better, but not as beneficial for natural language inference (NLI). In this paper, we analyze two primary flaws in the way NLEs are currently used to train explanation generators for language inference tasks. We find that the explanation generators do not take into account the variability inherent in human explanation of labels, and that the current explanation generation models generate spurious explanations. To overcome these limitations, we propose a novel framework, LIREx, that incorporates both a rationale-enabled explanation generator and an instance selector to select only relevant, plausible NLEs to augment NLI models. When evaluated on the standardized SNLI data set, LIREx achieved an accuracy of 91.87%, an improvement of 0.32 over the baseline and matching the best-reported performance on the data set. It also achieves significantly better performance than previous studies when transferred to the out-of-domain MultiNLI data set. Qualitative analysis shows that LIREx generates flexible, faithful, and relevant NLEs that allow the model to be more robust to spurious explanations. The code is available at https://github.com/zhaoxy92/LIREx.