 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultidimensional Membership Mixture Models
Aug 02, 2012

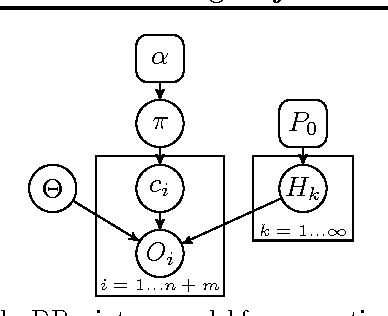
We present the multidimensional membership mixture (M3) models where every dimension of the membership represents an independent mixture model and each data point is generated from the selected mixture components jointly. This is helpful when the data has a certain shared structure. For example, three unique means and three unique variances can effectively form a Gaussian mixture model with nine components, while requiring only six parameters to fully describe it. In this paper, we present three instantiations of M3 models (together with the learning and inference algorithms): infinite, finite, and hybrid, depending on whether the number of mixtures is fixed or not. They are built upon Dirichlet process mixture models, latent Dirichlet allocation, and a combination respectively. We then consider two applications: topic modeling and learning 3D object arrangements. Our experiments show that our M3 models achieve better performance using fewer topics than many classic topic models. We also observe that topics from the different dimensions of M3 models are meaningful and orthogonal to each other.
Learning Object Arrangements in 3D Scenes using Human Context
Jun 27, 2012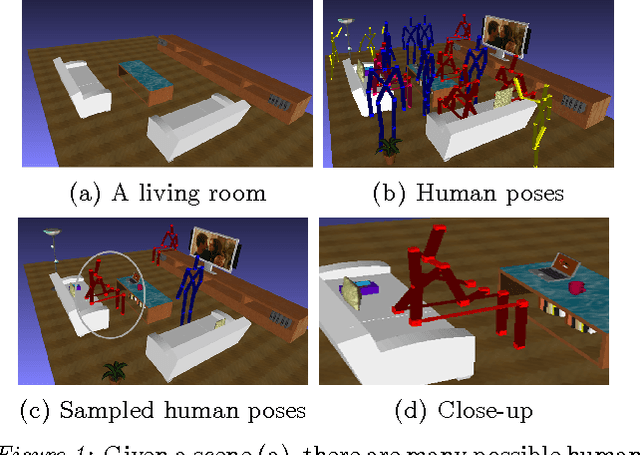
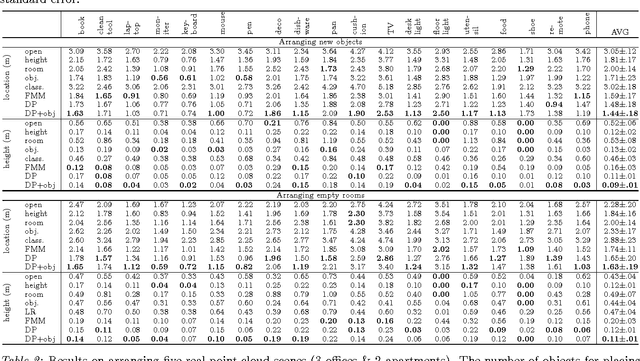
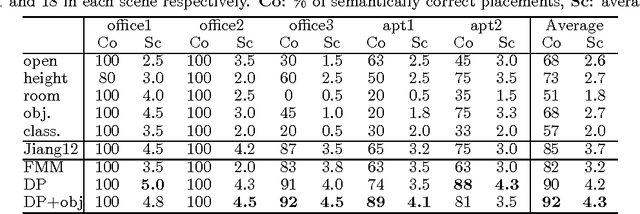
We consider the problem of learning object arrangements in a 3D scene. The key idea here is to learn how objects relate to human poses based on their affordances, ease of use and reachability. In contrast to modeling object-object relationships, modeling human-object relationships scales linearly in the number of objects. We design appropriate density functions based on 3D spatial features to capture this. We learn the distribution of human poses in a scene using a variant of the Dirichlet process mixture model that allows sharing of the density function parameters across the same object types. Then we can reason about arrangements of the objects in the room based on these meaningful human poses. In our extensive experiments on 20 different rooms with a total of 47 objects, our algorithm predicted correct placements with an average error of 1.6 meters from ground truth. In arranging five real scenes, it received a score of 4.3/5 compared to 3.7 for the best baseline method.
Learning to Place New Objects in a Scene
Feb 08, 2012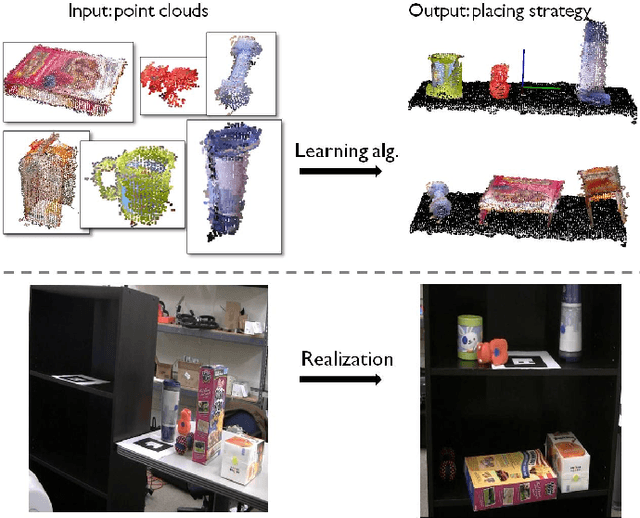



Placing is a necessary skill for a personal robot to have in order to perform tasks such as arranging objects in a disorganized room. The object placements should not only be stable but also be in their semantically preferred placing areas and orientations. This is challenging because an environment can have a large variety of objects and placing areas that may not have been seen by the robot before. In this paper, we propose a learning approach for placing multiple objects in different placing areas in a scene. Given point-clouds of the objects and the scene, we design appropriate features and use a graphical model to encode various properties, such as the stacking of objects, stability, object-area relationship and common placing constraints. The inference in our model is an integer linear program, which we solve efficiently via an LP relaxation. We extensively evaluate our approach on 98 objects from 16 categories being placed into 40 areas. Our robotic experiments show a success rate of 98% in placing known objects and 82% in placing new objects stably. We use our method on our robots for performing tasks such as loading several dish-racks, a bookshelf and a fridge with multiple items.
Learning to Place New Objects
Jun 17, 2011


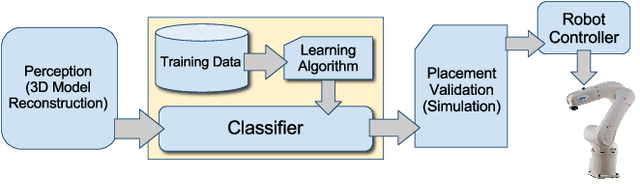
The ability to place objects in the environment is an important skill for a personal robot. An object should not only be placed stably, but should also be placed in its preferred location/orientation. For instance, a plate is preferred to be inserted vertically into the slot of a dish-rack as compared to be placed horizontally in it. Unstructured environments such as homes have a large variety of object types as well as of placing areas. Therefore our algorithms should be able to handle placing new object types and new placing areas. These reasons make placing a challenging manipulation task. In this work, we propose a supervised learning algorithm for finding good placements given the point-clouds of the object and the placing area. It learns to combine the features that capture support, stability and preferred placements using a shared sparsity structure in the parameters. Even when neither the object nor the placing area is seen previously in the training set, our algorithm predicts good placements. In extensive experiments, our method enables the robot to stably place several new objects in several new placing areas with 98% success-rate; and it placed the objects in their preferred placements in 92% of the cases.