 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Does RLHF Scale? Exploring the Impacts From Data, Model, and Method
Dec 08, 2024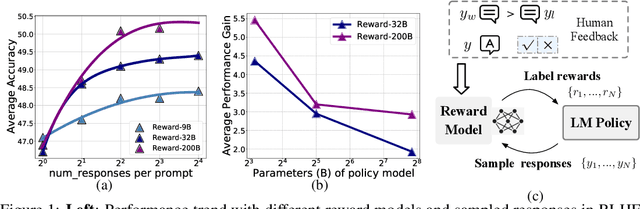
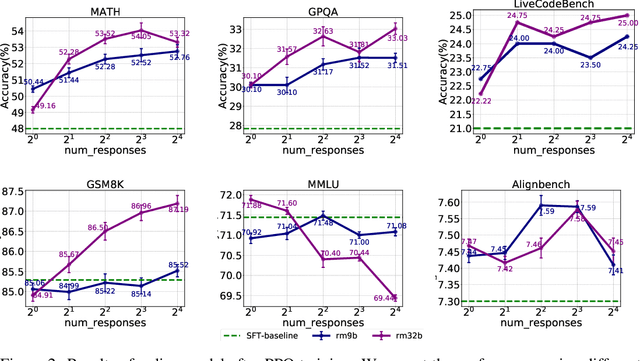
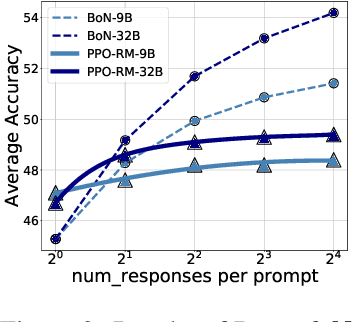
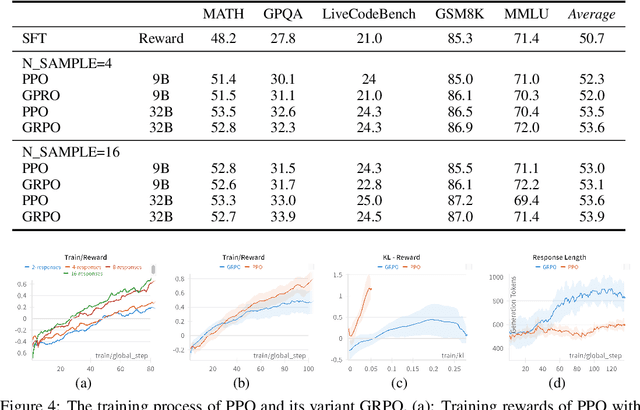
This study explores the scaling properties of Reinforcement Learning from Human Feedback (RLHF) in Large Language Models (LLMs). Although RLHF is considered an important step in post-training of LLMs, its scaling potential is still largely unknown. We systematically analyze key components in the RLHF framework--model size, data composition, and inference budget--and their impacts on performance. Our findings show that increasing data diversity and volume improves reward model performance, helping process-supervision models scale better. For policy training, more response samples per prompt boost performance initially but quickly plateau. And larger reward models offer modest gains in policy training. In addition, larger policy models benefit less from RLHF with a fixed reward model. Overall, RLHF scales less efficiently than pretraining, with diminishing returns from additional computational resources. Based on these observations, we propose strategies to optimize RLHF performance within computational limits.
ZhuJiu: A Multi-dimensional, Multi-faceted Chinese Benchmark for Large Language Models
Aug 28, 2023



The unprecedented performance of large language models (LLMs) requires comprehensive and accurate evaluation. We argue that for LLMs evaluation, benchmarks need to be comprehensive and systematic. To this end, we propose the ZhuJiu benchmark, which has the following strengths: (1) Multi-dimensional ability coverage: We comprehensively evaluate LLMs across 7 ability dimensions covering 51 tasks. Especially, we also propose a new benchmark that focuses on knowledge ability of LLMs. (2) Multi-faceted evaluation methods collaboration: We use 3 different yet complementary evaluation methods to comprehensively evaluate LLMs, which can ensure the authority and accuracy of the evaluation results. (3) Comprehensive Chinese benchmark: ZhuJiu is the pioneering benchmark that fully assesses LLMs in Chinese, while also providing equally robust evaluation abilities in English. (4) Avoiding potential data leakage: To avoid data leakage, we construct evaluation data specifically for 37 tasks. We evaluate 10 current mainstream LLMs and conduct an in-depth discussion and analysis of their results. The ZhuJiu benchmark and open-participation leaderboard are publicly released at http://www.zhujiu-benchmark.com/ and we also provide a demo video at https://youtu.be/qypkJ89L1Ic.