 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes RLHF Scale? Exploring the Impacts From Data, Model, and Method
Paper and Code
Dec 08, 2024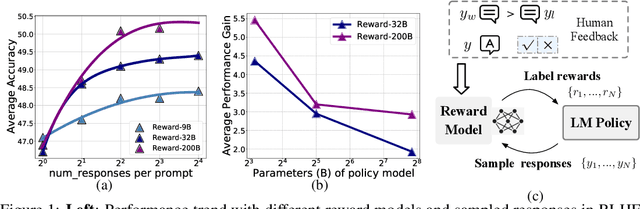
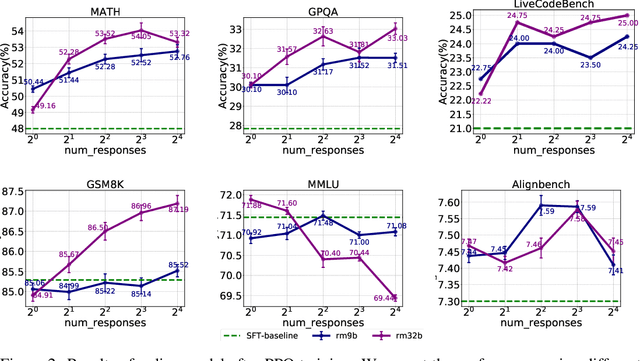
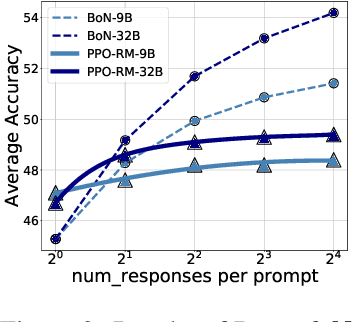
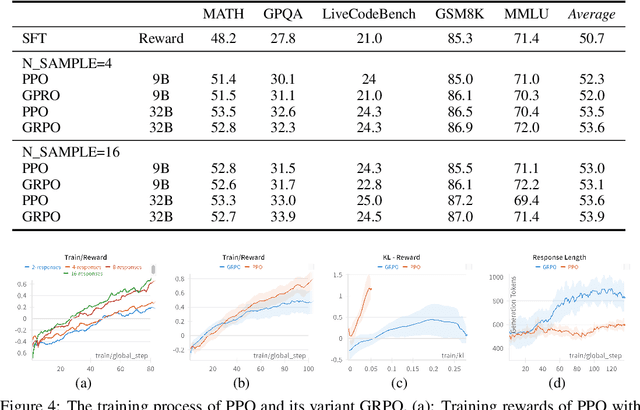
This study explores the scaling properties of Reinforcement Learning from Human Feedback (RLHF) in Large Language Models (LLMs). Although RLHF is considered an important step in post-training of LLMs, its scaling potential is still largely unknown. We systematically analyze key components in the RLHF framework--model size, data composition, and inference budget--and their impacts on performance. Our findings show that increasing data diversity and volume improves reward model performance, helping process-supervision models scale better. For policy training, more response samples per prompt boost performance initially but quickly plateau. And larger reward models offer modest gains in policy training. In addition, larger policy models benefit less from RLHF with a fixed reward model. Overall, RLHF scales less efficiently than pretraining, with diminishing returns from additional computational resources. Based on these observations, we propose strategies to optimize RLHF performance within computational limits.