 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling
Paper and Code
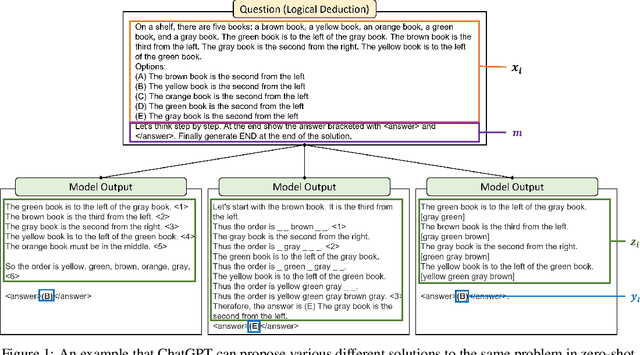
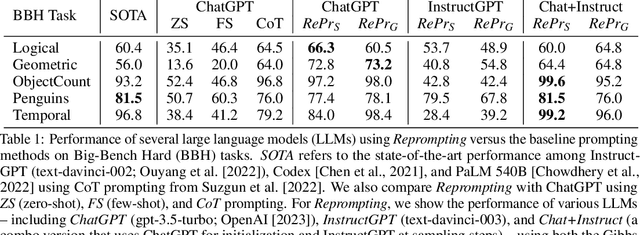
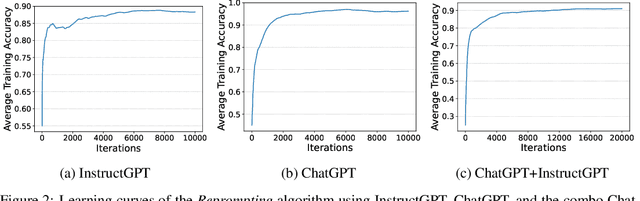

We introduce Reprompting, an iterative sampling algorithm that searches for the Chain-of-Thought (CoT) recipes for a given task without human intervention. Through Gibbs sampling, we infer CoT recipes that work consistently well for a set of training samples. Our method iteratively samples new recipes using previously sampled solutions as parent prompts to solve other training problems. On five Big-Bench Hard tasks that require multi-step reasoning, Reprompting achieves consistently better performance than the zero-shot, few-shot, and human-written CoT baselines. Reprompting can also facilitate transfer of knowledge from a stronger model to a weaker model leading to substantially improved performance of the weaker model. Overall, Reprompting brings up to +17 point improvements over the previous state-of-the-art method that uses human-written CoT prompts.