 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fire Thief Is Also the Keeper: Balancing Usability and Privacy in Prompts
Jun 20, 2024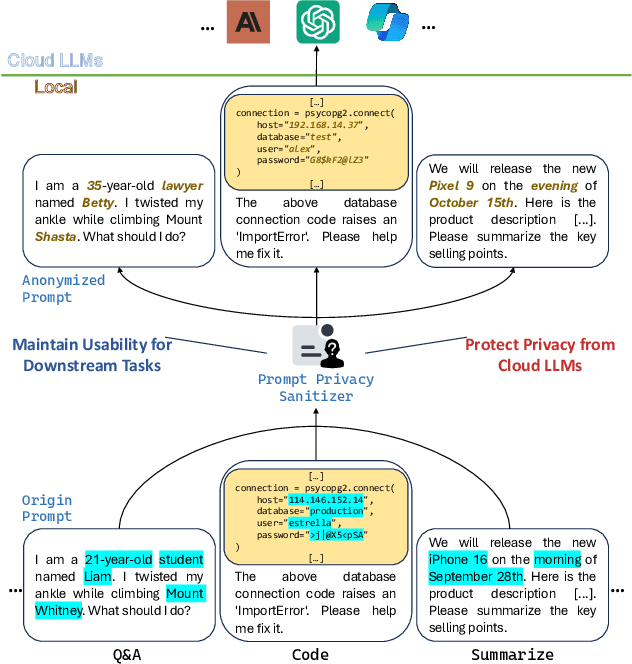
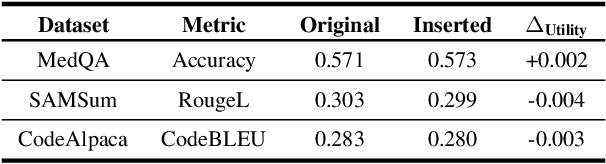
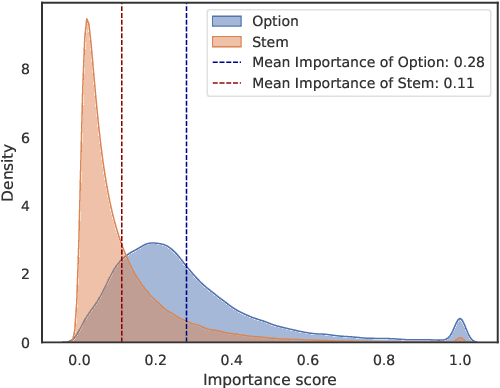
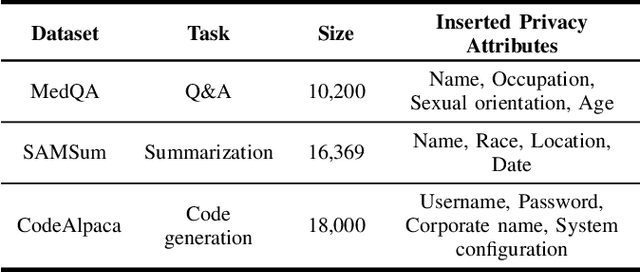
The rapid adoption of online chatbots represents a significant advancement in artificial intelligence. However, this convenience brings considerable privacy concerns, as prompts can inadvertently contain sensitive information exposed to large language models (LLMs). Limited by high computational costs, reduced task usability, and excessive system modifications, previous works based on local deployment, embedding perturbation, and homomorphic encryption are inapplicable to online prompt-based LLM applications. To address these issues, this paper introduces Prompt Privacy Sanitizer (i.e., ProSan), an end-to-end prompt privacy protection framework that can produce anonymized prompts with contextual privacy removed while maintaining task usability and human readability. It can also be seamlessly integrated into the online LLM service pipeline. To achieve high usability and dynamic anonymity, ProSan flexibly adjusts its protection targets and strength based on the importance of the words and the privacy leakage risk of the prompts. Additionally, ProSan is capable of adapting to diverse computational resource conditions, ensuring privacy protection even for mobile devices with limited computing power. Our experiments demonstrate that ProSan effectively removes private information across various tasks, including question answering, text summarization, and code generation, with minimal reduction in task performance.
LabObf: A Label Protection Scheme for Vertical Federated Learning Through Label Obfuscation
May 27, 2024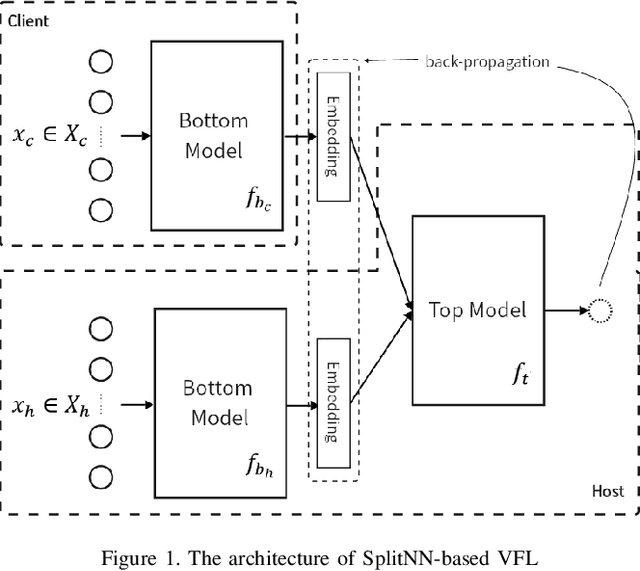

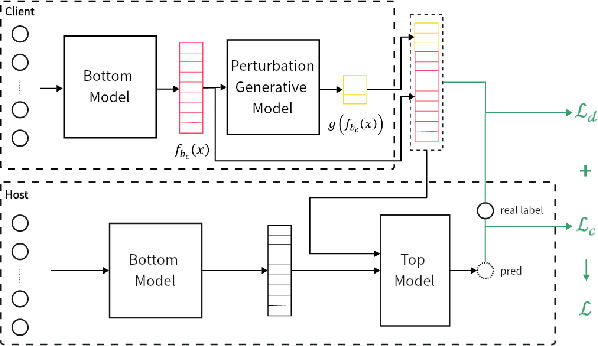

Split learning, as one of the most common architectures in vertical federated learning, has gained widespread use in industry due to its privacy-preserving characteristics. In this architecture, the party holding the labels seeks cooperation from other parties to improve model performance due to insufficient feature data. Each of these participants has a self-defined bottom model to learn hidden representations from its own feature data and uploads the embedding vectors to the top model held by the label holder for final predictions. This design allows participants to conduct joint training without directly exchanging data. However, existing research points out that malicious participants may still infer label information from the uploaded embeddings, leading to privacy leakage. In this paper, we first propose an embedding extension attack that manually modifies embeddings to undermine existing defense strategies, which rely on constraining the correlation between the embeddings uploaded by participants and the labels. Subsequently, we propose a new label obfuscation defense strategy, called `LabObf', which randomly maps each original one-hot vector label to multiple numerical soft labels with values intertwined, significantly increasing the difficulty for attackers to infer the labels. We conduct experiments on four different types of datasets, and the results show that LabObf can reduce the attacker's success rate to near random guessing while maintaining an acceptable model accuracy.
Subtoxic Questions: Dive Into Attitude Change of LLM's Response in Jailbreak Attempts
Apr 12, 2024

As Large Language Models (LLMs) of Prompt Jailbreaking are getting more and more attention, it is of great significance to raise a generalized research paradigm to evaluate attack strengths and a basic model to conduct subtler experiments. In this paper, we propose a novel approach by focusing on a set of target questions that are inherently more sensitive to jailbreak prompts, aiming to circumvent the limitations posed by enhanced LLM security. Through designing and analyzing these sensitive questions, this paper reveals a more effective method of identifying vulnerabilities in LLMs, thereby contributing to the advancement of LLM security. This research not only challenges existing jailbreaking methodologies but also fortifies LLMs against potential exploits.
Optimization of the energy efficiency in Smart Internet of Vehicles assisted by MEC
Jan 14, 2023Smart Internet of Vehicles (IoV) as a promising application in Internet of Things (IoT) emerges with the development of the fifth generation mobile communication (5G). Nevertheless, the heterogeneous requirements of sufficient battery capacity, powerful computing ability and energy efficiency for electric vehicles face great challenges due to the explosive data growth in 5G and the sixth generation of mobile communication (6G) networks. In order to alleviate the deficiencies mentioned above, this paper proposes a mobile edge computing (MEC) enabled IoV system, in which electric vehicle nodes (eVNs) upload and download data through an anchor node (AN) which is integrated with a MEC server. Meanwhile, the anchor node transmitters radio signal to electric vehicles with simultaneous wireless information and power transfer (SWIPT) technology so as to compensate the battery limitation of eletric vehicles. Moreover, the spectrum efficiency is further improved by multi-input and multi-output (MIMO) and full-duplex (FD) technologies which is equipped at the anchor node. In consideration of the issues above, we maximize the average energy efficiency of electric vehicles by jointly optimize the CPU frequency, vehicle transmitting power, computing tasks and uplink rate. Since the problem is nonconvex, we propose a novel alternate interior-point iterative scheme (AIIS) under the constraints of computing tasks, energy consumption and time latency. Results and discussion section verifies the effectiveness of the proposed AIIS scheme comparing with the benchmark schemes.
* 17 pages, 9 figures, EURASIP J. Adv. Signal Process