 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Preserving LLM Inference via Collaborative Obfuscation (Technical Report)
Mar 02, 2026The rapid development of large language models (LLMs) has driven the widespread adoption of cloud-based LLM inference services, while also bringing prominent privacy risks associated with the transmission and processing of private data in remote inference. For privacy-preserving LLM inference technologies to be practically applied in industrial scenarios, three core requirements must be satisfied simultaneously: (1) Accuracy and efficiency losses should be minimized to mitigate degradation in service experience. (2) The inference process can be run on large-scale clusters consist of heterogeneous legacy xPUs. (3) Compatibility with existing LLM infrastructures should be ensured to reuse their engineering optimizations. To the best of our knowledge, none of the existing privacy-preserving LLM inference methods satisfy all the above constraints while delivering meaningful privacy guarantees. In this paper, we propose AloePri, the first privacy-preserving LLM inference method for industrial applications. AloePri protects both the input and output data by covariant obfuscation, which jointly transforms data and model parameters to achieve better accuracy and privacy. We carefully design the transformation for each model component to ensure inference accuracy and data privacy while keeping full compatibility with existing infrastructures of Language Model as a Service. AloePri has been integrated into an industrial system for the evaluation of mainstream LLMs. The evaluation on Deepseek-V3.1-Terminus model (671B parameters) demonstrates that AloePri causes accuracy loss of 0.0%~3.5% and exhibits efficiency equivalent to that of plaintext inference. Meanwhile, AloePri successfully resists state-of-the-art attacks, with less than 5\% of tokens recovered. To the best of our knowledge, AloePri is the first method to exhibit practical applicability to large-scale models in real-world systems.
On Evaluating the Poisoning Robustness of Federated Learning under Local Differential Privacy
Sep 05, 2025Federated learning (FL) combined with local differential privacy (LDP) enables privacy-preserving model training across decentralized data sources. However, the decentralized data-management paradigm leaves LDPFL vulnerable to participants with malicious intent. The robustness of LDPFL protocols, particularly against model poisoning attacks (MPA), where adversaries inject malicious updates to disrupt global model convergence, remains insufficiently studied. In this paper, we propose a novel and extensible model poisoning attack framework tailored for LDPFL settings. Our approach is driven by the objective of maximizing the global training loss while adhering to local privacy constraints. To counter robust aggregation mechanisms such as Multi-Krum and trimmed mean, we develop adaptive attacks that embed carefully crafted constraints into a reverse training process, enabling evasion of these defenses. We evaluate our framework across three representative LDPFL protocols, three benchmark datasets, and two types of deep neural networks. Additionally, we investigate the influence of data heterogeneity and privacy budgets on attack effectiveness. Experimental results demonstrate that our adaptive attacks can significantly degrade the performance of the global model, revealing critical vulnerabilities and highlighting the need for more robust LDPFL defense strategies against MPA. Our code is available at https://github.com/ZiJW/LDPFL-Attack
LabObf: A Label Protection Scheme for Vertical Federated Learning Through Label Obfuscation
May 27, 2024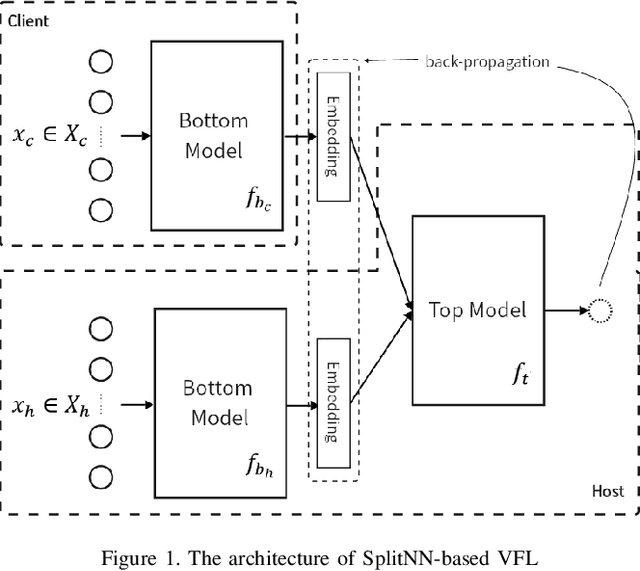


Split learning, as one of the most common architectures in vertical federated learning, has gained widespread use in industry due to its privacy-preserving characteristics. In this architecture, the party holding the labels seeks cooperation from other parties to improve model performance due to insufficient feature data. Each of these participants has a self-defined bottom model to learn hidden representations from its own feature data and uploads the embedding vectors to the top model held by the label holder for final predictions. This design allows participants to conduct joint training without directly exchanging data. However, existing research points out that malicious participants may still infer label information from the uploaded embeddings, leading to privacy leakage. In this paper, we first propose an embedding extension attack that manually modifies embeddings to undermine existing defense strategies, which rely on constraining the correlation between the embeddings uploaded by participants and the labels. Subsequently, we propose a new label obfuscation defense strategy, called `LabObf', which randomly maps each original one-hot vector label to multiple numerical soft labels with values intertwined, significantly increasing the difficulty for attackers to infer the labels. We conduct experiments on four different types of datasets, and the results show that LabObf can reduce the attacker's success rate to near random guessing while maintaining an acceptable model accuracy.
A Split-and-Privatize Framework for Large Language Model Fine-Tuning
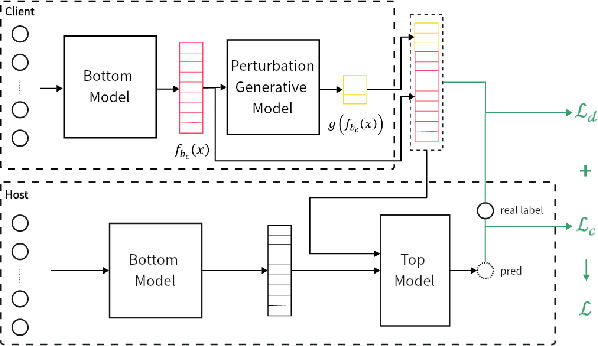
Dec 25, 2023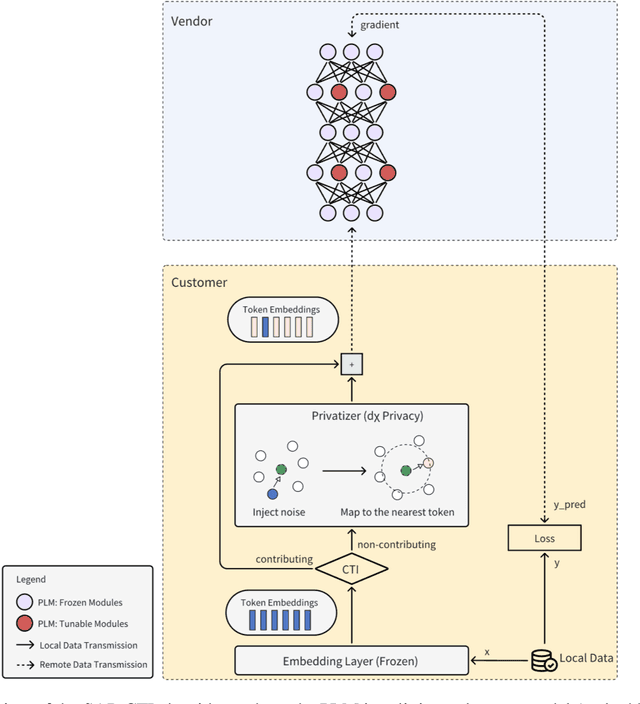


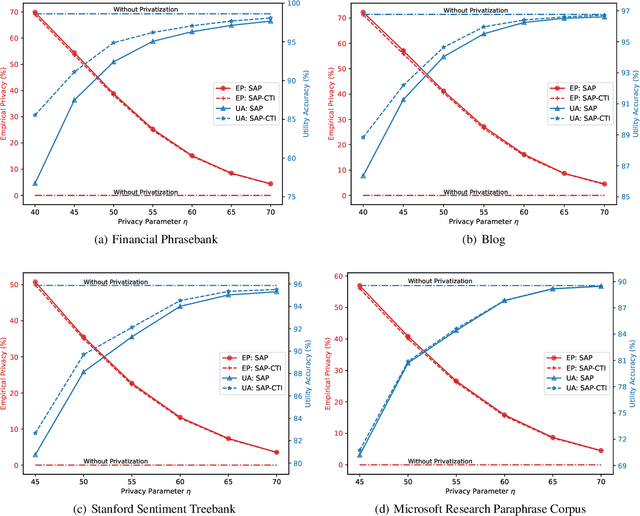
Fine-tuning is a prominent technique to adapt a pre-trained language model to downstream scenarios. In parameter-efficient fine-tuning, only a small subset of modules are trained over the downstream datasets, while leaving the rest of the pre-trained model frozen to save computation resources. In recent years, a popular productization form arises as Model-as-a-Service (MaaS), in which vendors provide abundant pre-trained language models, server resources and core functions, and customers can fine-tune, deploy and invoke their customized model by accessing the one-stop MaaS with their own private dataset. In this paper, we identify the model and data privacy leakage risks in MaaS fine-tuning, and propose a Split-and-Privatize (SAP) framework, which manage to mitigate the privacy issues by adapting the existing split learning architecture. The proposed SAP framework is sufficiently investigated by experiments, and the results indicate that it can enhance the empirical privacy by 62% at the cost of 1% model performance degradation on the Stanford Sentiment Treebank dataset.
Secure Split Learning against Property Inference, Data Reconstruction, and Feature Space Hijacking Attacks
Apr 19, 2023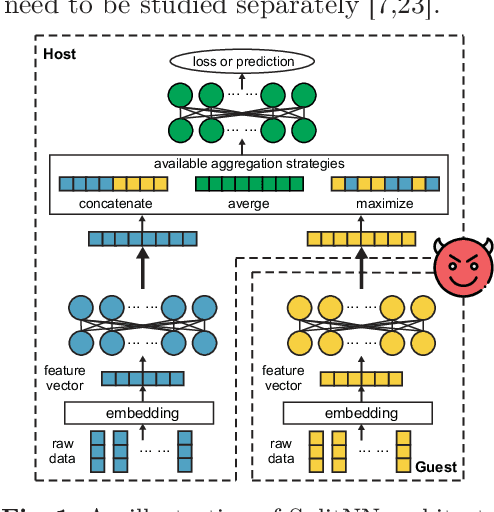
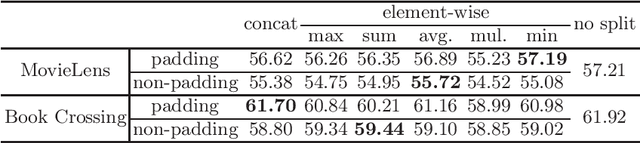
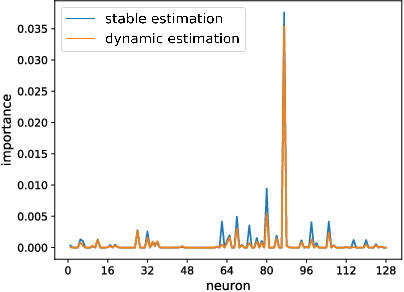

Split learning of deep neural networks (SplitNN) has provided a promising solution to learning jointly for the mutual interest of a guest and a host, which may come from different backgrounds, holding features partitioned vertically. However, SplitNN creates a new attack surface for the adversarial participant, holding back its practical use in the real world. By investigating the adversarial effects of highly threatening attacks, including property inference, data reconstruction, and feature hijacking attacks, we identify the underlying vulnerability of SplitNN and propose a countermeasure. To prevent potential threats and ensure the learning guarantees of SplitNN, we design a privacy-preserving tunnel for information exchange between the guest and the host. The intuition is to perturb the propagation of knowledge in each direction with a controllable unified solution. To this end, we propose a new activation function named R3eLU, transferring private smashed data and partial loss into randomized responses in forward and backward propagations, respectively. We give the first attempt to secure split learning against three threatening attacks and present a fine-grained privacy budget allocation scheme. The analysis proves that our privacy-preserving SplitNN solution provides a tight privacy budget, while the experimental results show that our solution performs better than existing solutions in most cases and achieves a good tradeoff between defense and model usability.