 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Augmentation in CLIP for Improved Anatomy Detection on Multi-modal Medical Images
Paper and Code
May 31, 2024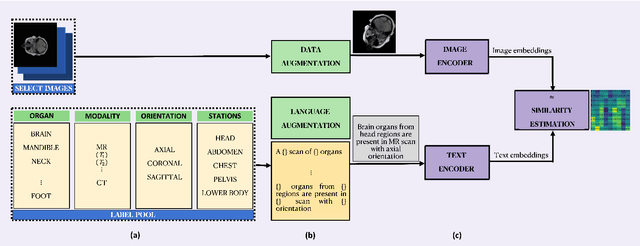
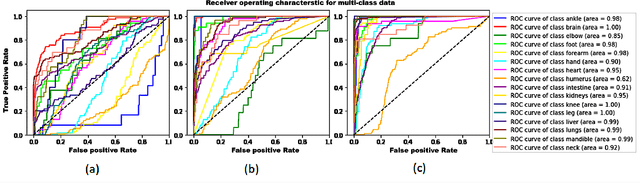
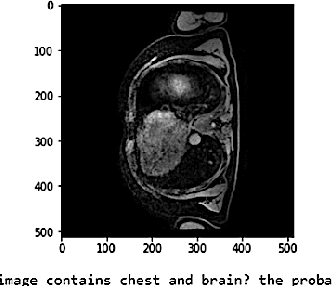
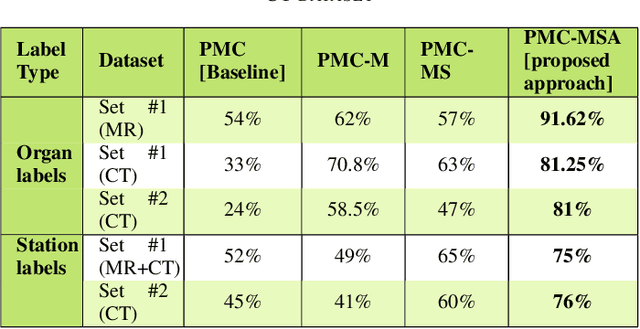
Vision-language models have emerged as a powerful tool for previously challenging multi-modal classification problem in the medical domain. This development has led to the exploration of automated image description generation for multi-modal clinical scans, particularly for radiology report generation. Existing research has focused on clinical descriptions for specific modalities or body regions, leaving a gap for a model providing entire-body multi-modal descriptions. In this paper, we address this gap by automating the generation of standardized body station(s) and list of organ(s) across the whole body in multi-modal MR and CT radiological images. Leveraging the versatility of the Contrastive Language-Image Pre-training (CLIP), we refine and augment the existing approach through multiple experiments, including baseline model fine-tuning, adding station(s) as a superset for better correlation between organs, along with image and language augmentations. Our proposed approach demonstrates 47.6% performance improvement over baseline PubMedCLIP.