 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgehf0: A hybrid pitch extraction method for multimodal voice
Apr 22, 2019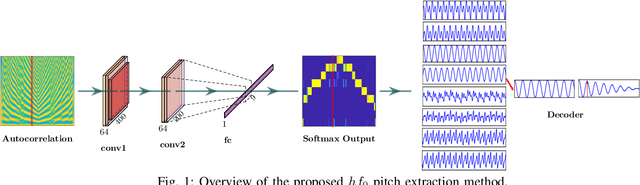
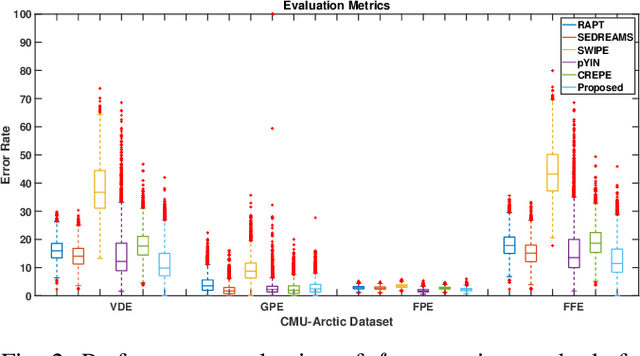
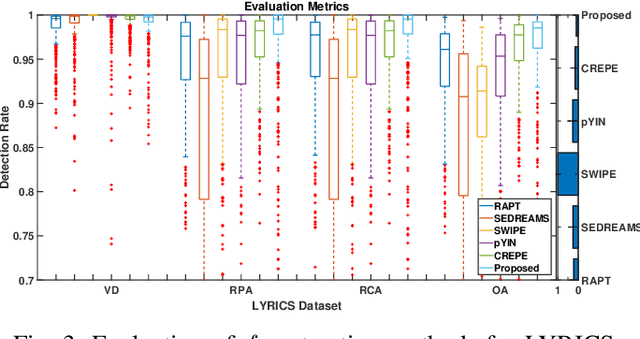

Pitch or fundamental frequency (f0) extraction is a fundamental problem studied extensively for its potential applications in speech and clinical applications. In literature, explicit mode specific (modal speech or singing voice or emotional/ expressive speech or noisy speech) signal processing and deep learning f0 extraction methods that exploit the quasi periodic nature of the signal in time, harmonic property in spectral or combined form to extract the pitch is developed. Hence, there is no single unified method which can reliably extract the pitch from various modes of the acoustic signal. In this work, we propose a hybrid f0 extraction method which seamlessly extracts the pitch across modes of speech production with very high accuracy required for many applications. The proposed hybrid model exploits the advantages of deep learning and signal processing methods to minimize the pitch detection error and adopts to various modes of acoustic signal. Specifically, we propose an ordinal regression convolutional neural networks to map the periodicity rich input representation to obtain the nominal pitch classes which drastically reduces the number of classes required for pitch detection unlike other deep learning approaches. Further, the accurate f0 is estimated from the nominal pitch class labels by filtering and autocorrelation. We show that the proposed method generalizes to the unseen modes of voice production and various noises for large scale datasets. Also, the proposed hybrid model significantly reduces the learning parameters required to train the deep model compared to other methods. Furthermore,the evaluation measures showed that the proposed method is significantly better than the state-of-the-art signal processing and deep learning approaches.