 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Adversaries, yet Faltering to Noise? Leveraging Conditional Variational AutoEncoders for Adversary Detection in the Presence of Noisy Images
Paper and Code
Dec 09, 2021

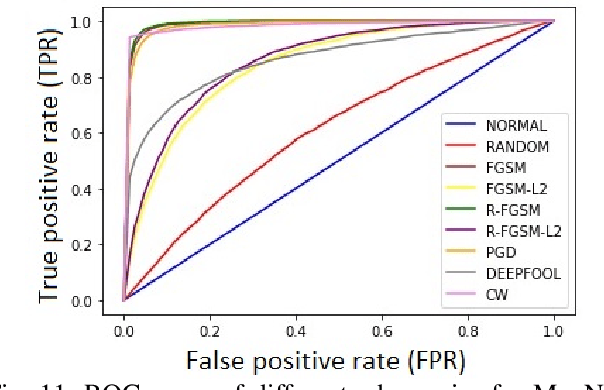
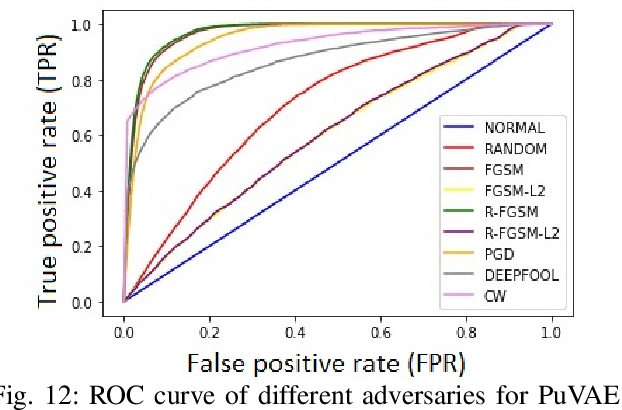
With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. What is so special in the slightest intelligent perturbations or noise additions over normal images that it leads to catastrophic classifications by the deep neural networks? Using statistical hypothesis testing, we find that Conditional Variational AutoEncoders (CVAE) are surprisingly good at detecting imperceptible image perturbations. In this paper, we show how CVAEs can be effectively used to detect adversarial attacks on image classification networks. We demonstrate our results over MNIST, CIFAR-10 dataset and show how our method gives comparable performance to the state-of-the-art methods in detecting adversaries while not getting confused with noisy images, where most of the existing methods falter.