 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieveGPT: Merging Prompts and Mathematical Models for Enhanced Code-Mixed Information Retrieval
Paper and Code
Nov 07, 2024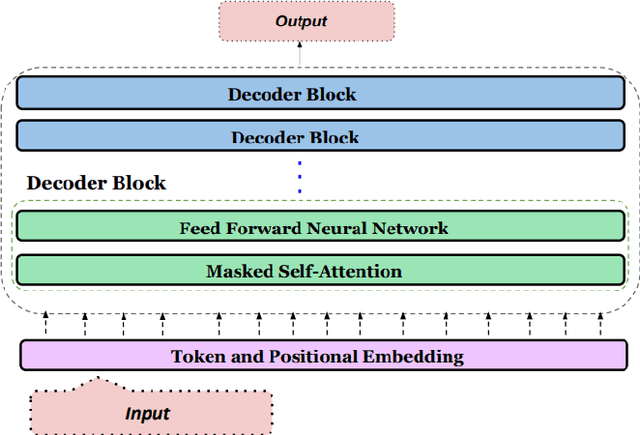
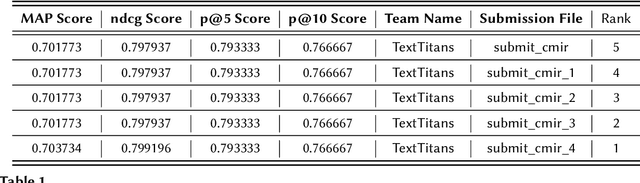
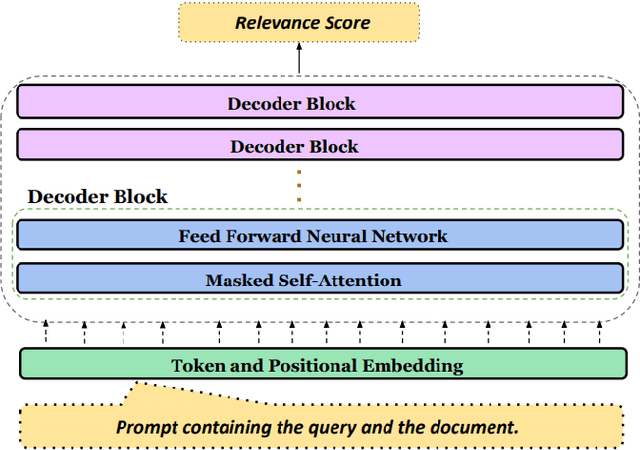
Code-mixing, the integration of lexical and grammatical elements from multiple languages within a single sentence, is a widespread linguistic phenomenon, particularly prevalent in multilingual societies. In India, social media users frequently engage in code-mixed conversations using the Roman script, especially among migrant communities who form online groups to share relevant local information. This paper focuses on the challenges of extracting relevant information from code-mixed conversations, specifically within Roman transliterated Bengali mixed with English. This study presents a novel approach to address these challenges by developing a mechanism to automatically identify the most relevant answers from code-mixed conversations. We have experimented with a dataset comprising of queries and documents from Facebook, and Query Relevance files (QRels) to aid in this task. Our results demonstrate the effectiveness of our approach in extracting pertinent information from complex, code-mixed digital conversations, contributing to the broader field of natural language processing in multilingual and informal text environments. We use GPT-3.5 Turbo via prompting alongwith using the sequential nature of relevant documents to frame a mathematical model which helps to detect relevant documents corresponding to a query.