 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPROVE: Improving Medical Plausibility without Reliance on HumanValidation -- An Enhanced Prototype-Guided Diffusion Framework
Nov 26, 2024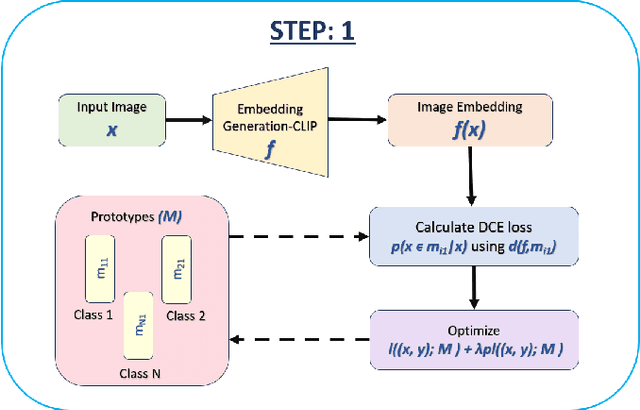

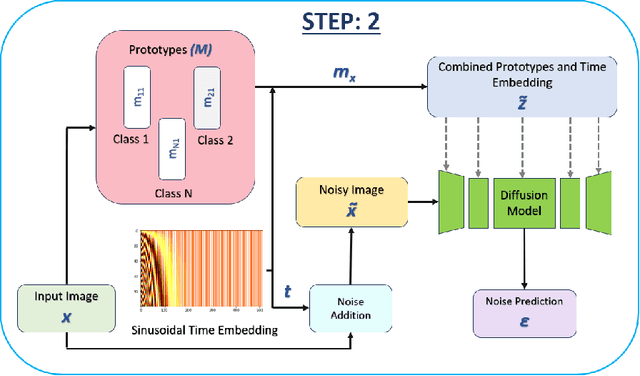
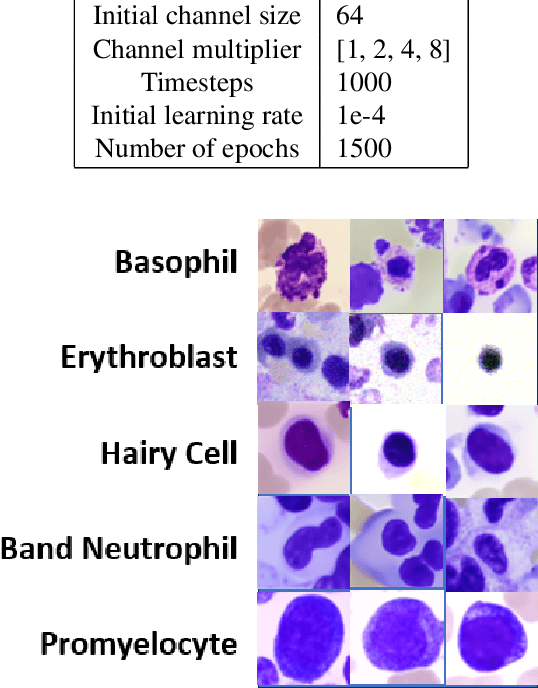
Generative models have proven to be very effective in generating synthetic medical images and find applications in downstream tasks such as enhancing rare disease datasets, long-tailed dataset augmentation, and scaling machine learning algorithms. For medical applications, the synthetically generated medical images by such models are still reasonable in quality when evaluated based on traditional metrics such as FID score, precision, and recall. However, these metrics fail to capture the medical/biological plausibility of the generated images. Human expert feedback has been used to get biological plausibility which demonstrates that these generated images have very low plausibility. Recently, the research community has further integrated this human feedback through Reinforcement Learning from Human Feedback(RLHF), which generates more medically plausible images. However, incorporating human feedback is a costly and slow process. In this work, we propose a novel approach to improve the medical plausibility of generated images without the need for human feedback. We introduce IMPROVE:Improving Medical Plausibility without Reliance on Human Validation - An Enhanced Prototype-Guided Diffusion Framework, a prototype-guided diffusion process for medical image generation and show that it substantially enhances the biological plausibility of the generated medical images without the need for any human feedback. We perform experiments on Bone Marrow and HAM10000 datasets and show that medical accuracy can be substantially increased without human feedback.
INSITE: labelling medical images using submodular functions and semi-supervised data programming
Feb 11, 2024
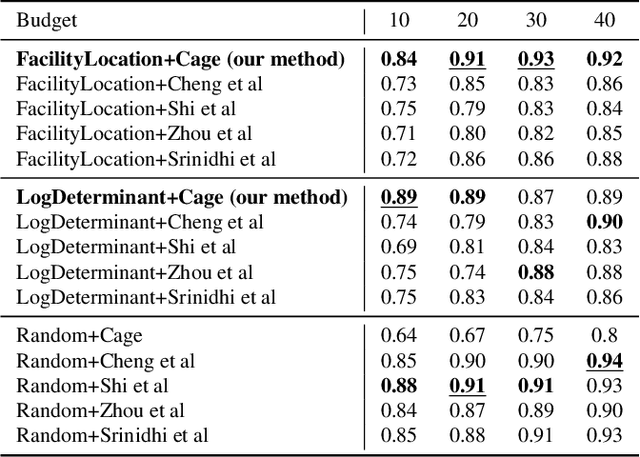
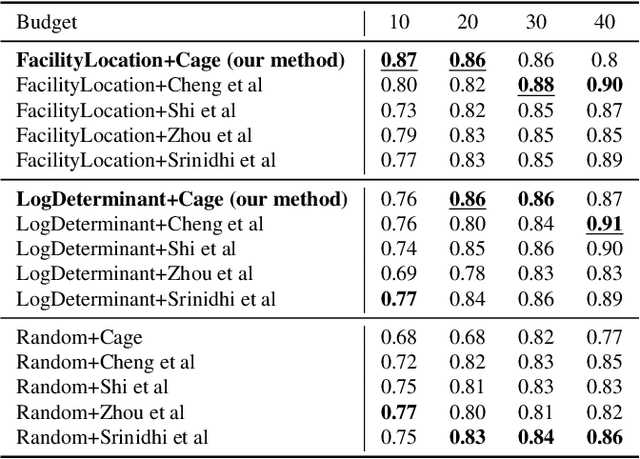
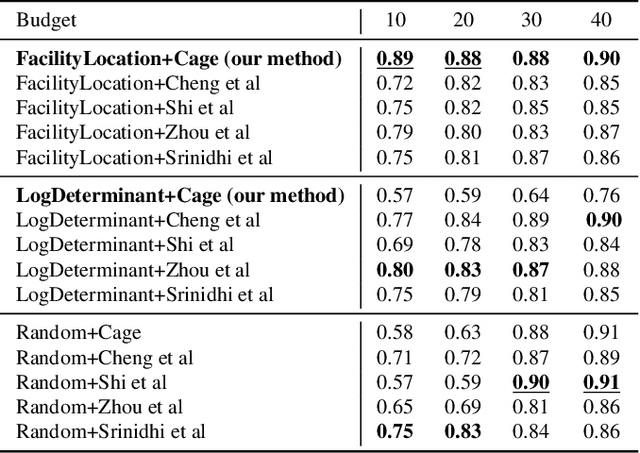
The necessity of large amounts of labeled data to train deep models, especially in medical imaging creates an implementation bottleneck in resource-constrained settings. In Insite (labelINg medical imageS usIng submodular funcTions and sEmi-supervised data programming) we apply informed subset selection to identify a small number of most representative or diverse images from a huge pool of unlabelled data subsequently annotated by a domain expert. The newly annotated images are then used as exemplars to develop several data programming-driven labeling functions. These labelling functions output a predicted-label and a similarity score when given an unlabelled image as an input. A consensus is brought amongst the outputs of these labeling functions by using a label aggregator function to assign the final predicted label to each unlabelled data point. We demonstrate that informed subset selection followed by semi-supervised data programming methods using these images as exemplars perform better than other state-of-the-art semi-supervised methods. Further, for the first time we demonstrate that this can be achieved through a small set of images used as exemplars.
Realistic River Image Synthesis using Deep Generative Adversarial Networks
Mar 03, 2020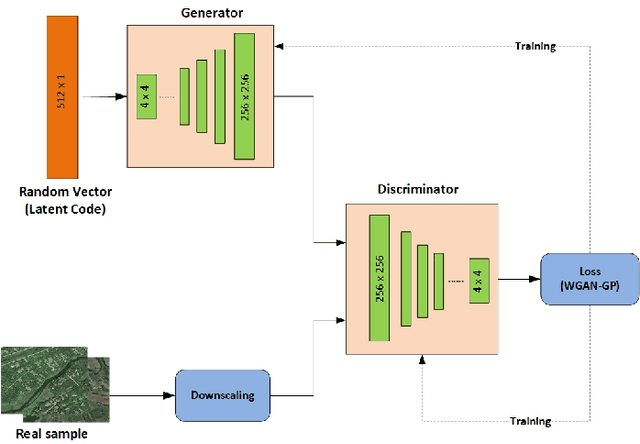


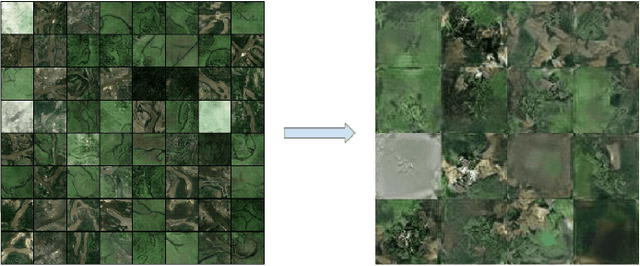
In this paper, we investigate an application of image generation for river satellite imagery. Specifically, we propose a generative adversarial network (GAN) model capable of generating high-resolution and realistic river images that can be used to support models in surface water estimation, river meandering, wetland loss and other hydrological research studies. First, we summarized an augmented, diverse repository of overhead river images to be used in training. Second, we incorporate the Progressive Growing GAN (PGGAN), a network architecture that iteratively trains smaller-resolution GANs to gradually build up to a very high resolution, to generate 256x256 river satellite imagery. With conventional GAN architectures, difficulties soon arise in terms of exponential increase of training time and vanishing/exploding gradient issues, which the PGGAN implementation seems to significantly reduce. Our preliminary results show great promise in capturing the detail of river flow and green areas present in river satellite images that can be used for supporting hydroinformatics studies.