 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrishtiKon: Multi-Granular Visual Grounding for Text-Rich Document Images
Jun 26, 2025



Visual grounding in text-rich document images is a critical yet underexplored challenge for document intelligence and visual question answering (VQA) systems. We present \drishtikon, a multi-granular visual grounding framework designed to enhance interpretability and trust in VQA for complex, multilingual documents. Our approach integrates robust multi-lingual OCR, large language models, and a novel region matching algorithm to accurately localize answer spans at block, line, word, and point levels. We curate a new benchmark from the CircularsVQA test set, providing fine-grained, human-verified annotations across multiple granularities. Extensive experiments demonstrate that our method achieves state-of-the-art grounding accuracy, with line-level granularity offering the best trade-off between precision and recall. Ablation studies further highlight the benefits of multi-block and multi-line reasoning. Comparative evaluations with leading vision-language models reveal the limitations of current VLMs in precise localization, underscoring the effectiveness of our structured, alignment-based approach. Our findings pave the way for more robust and interpretable document understanding systems in real-world, text-centric scenarios. Code and dataset has been made available at https://github.com/kasuba-badri-vishal/DhrishtiKon.
SPRINT: Script-agnostic Structure Recognition in Tables
Mar 15, 2025Table Structure Recognition (TSR) is vital for various downstream tasks like information retrieval, table reconstruction, and document understanding. While most state-of-the-art (SOTA) research predominantly focuses on TSR in English documents, the need for similar capabilities in other languages is evident, considering the global diversity of data. Moreover, creating substantial labeled data in non-English languages and training these SOTA models from scratch is costly and time-consuming. We propose TSR as a language-agnostic cell arrangement prediction and introduce SPRINT, Script-agnostic Structure Recognition in Tables. SPRINT uses recently introduced Optimized Table Structure Language (OTSL) sequences to predict table structures. We show that when coupled with a pre-trained table grid estimator, SPRINT can improve the overall tree edit distance-based similarity structure scores of tables even for non-English documents. We experimentally evaluate our performance across benchmark TSR datasets including PubTabNet, FinTabNet, and PubTables-1M. Our findings reveal that SPRINT not only matches SOTA models in performance on standard datasets but also demonstrates lower latency. Additionally, SPRINT excels in accurately identifying table structures in non-English documents, surpassing current leading models by showing an absolute average increase of 11.12%. We also present an algorithm for converting valid OTSL predictions into a widely used HTML-based table representation. To encourage further research, we release our code and Multilingual Scanned and Scene Table Structure Recognition Dataset, MUSTARD labeled with OTSL sequences for 1428 tables in thirteen languages encompassing several scripts at https://github.com/IITB-LEAP-OCR/SPRINT
PLATTER: A Page-Level Handwritten Text Recognition System for Indic Scripts
Feb 10, 2025In recent years, the field of Handwritten Text Recognition (HTR) has seen the emergence of various new models, each claiming to perform competitively better than the other in specific scenarios. However, making a fair comparison of these models is challenging due to inconsistent choices and diversity in test sets. Furthermore, recent advancements in HTR often fail to account for the diverse languages, especially Indic languages, likely due to the scarcity of relevant labeled datasets. Moreover, much of the previous work has focused primarily on character-level or word-level recognition, overlooking the crucial stage of Handwritten Text Detection (HTD) necessary for building a page-level end-to-end handwritten OCR pipeline. Through our paper, we address these gaps by making three pivotal contributions. Firstly, we present an end-to-end framework for Page-Level hAndwriTTen TExt Recognition (PLATTER) by treating it as a two-stage problem involving word-level HTD followed by HTR. This approach enables us to identify, assess, and address challenges in each stage independently. Secondly, we demonstrate the usage of PLATTER to measure the performance of our language-agnostic HTD model and present a consistent comparison of six trained HTR models on ten diverse Indic languages thereby encouraging consistent comparisons. Finally, we also release a Corpus of Handwritten Indic Scripts (CHIPS), a meticulously curated, page-level Indic handwritten OCR dataset labeled for both detection and recognition purposes. Additionally, we release our code and trained models, to encourage further contributions in this direction.
Can AI Assistance Aid in the Grading of Handwritten Answer Sheets?
Aug 23, 2024With recent advancements in artificial intelligence (AI), there has been growing interest in using state of the art (SOTA) AI solutions to provide assistance in grading handwritten answer sheets. While a few commercial products exist, the question of whether AI-assistance can actually reduce grading effort and time has not yet been carefully considered in published literature. This work introduces an AI-assisted grading pipeline. The pipeline first uses text detection to automatically detect question regions present in a question paper PDF. Next, it uses SOTA text detection methods to highlight important keywords present in the handwritten answer regions of scanned answer sheets to assist in the grading process. We then evaluate a prototype implementation of the AI-assisted grading pipeline deployed on an existing e-learning management platform. The evaluation involves a total of 5 different real-life examinations across 4 different courses at a reputed institute; it consists of a total of 42 questions, 17 graders, and 468 submissions. We log and analyze the grading time for each handwritten answer while using AI assistance and without it. Our evaluations have shown that, on average, the graders take 31% less time while grading a single response and 33% less grading time while grading a single answer sheet using AI assistance.
TEXTRON: Weakly Supervised Multilingual Text Detection through Data Programming
Feb 15, 2024Several recent deep learning (DL) based techniques perform considerably well on image-based multilingual text detection. However, their performance relies heavily on the availability and quality of training data. There are numerous types of page-level document images consisting of information in several modalities, languages, fonts, and layouts. This makes text detection a challenging problem in the field of computer vision (CV), especially for low-resource or handwritten languages. Furthermore, there is a scarcity of word-level labeled data for text detection, especially for multilingual settings and Indian scripts that incorporate both printed and handwritten text. Conventionally, Indian script text detection requires training a DL model on plenty of labeled data, but to the best of our knowledge, no relevant datasets are available. Manual annotation of such data requires a lot of time, effort, and expertise. In order to solve this problem, we propose TEXTRON, a Data Programming-based approach, where users can plug various text detection methods into a weak supervision-based learning framework. One can view this approach to multilingual text detection as an ensemble of different CV-based techniques and DL approaches. TEXTRON can leverage the predictions of DL models pre-trained on a significant amount of language data in conjunction with CV-based methods to improve text detection in other languages. We demonstrate that TEXTRON can improve the detection performance for documents written in Indian languages, despite the absence of corresponding labeled data. Further, through extensive experimentation, we show improvement brought about by our approach over the current State-of-the-art (SOTA) models, especially for handwritten Devanagari text. Code and dataset has been made available at https://github.com/IITB-LEAP-OCR/TEXTRON
A Deep Recurrent Framework for Cleaning Motion Capture Data
Dec 09, 2017
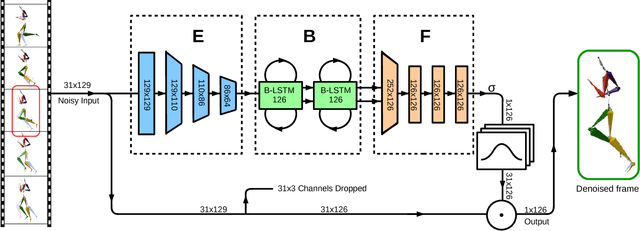

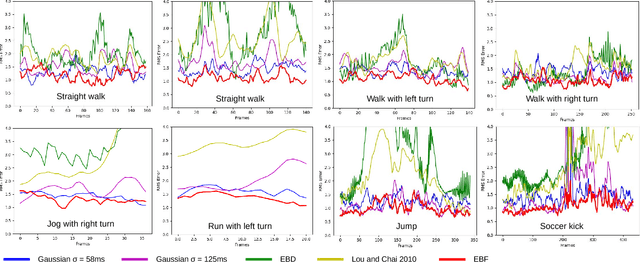
We present a deep, bidirectional, recurrent framework for cleaning noisy and incomplete motion capture data. It exploits temporal coherence and joint correlations to infer adaptive filters for each joint in each frame. A single model can be trained to denoise a heterogeneous mix of action types, under substantial amounts of noise. A signal that has both noise and gaps is preprocessed with a second bidirectional network that synthesizes missing frames from surrounding context. The approach handles a wide variety of noise types and long gaps, does not rely on knowledge of the noise distribution, and operates in a streaming setting. We validate our approach through extensive evaluations on noise both in joint angles and in joint positions, and show that it improves upon various alternatives.