 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Multi-modal Gradient Attention for Explainable Composed Image Retrieval
Paper and Code
Aug 31, 2023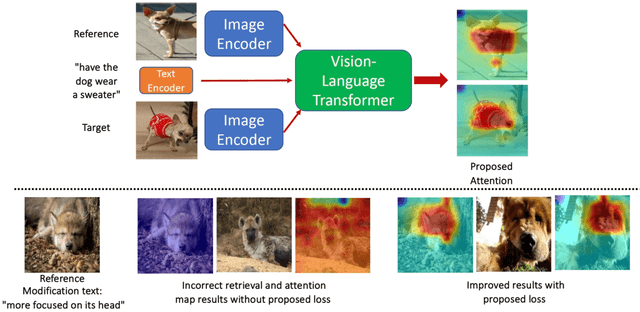

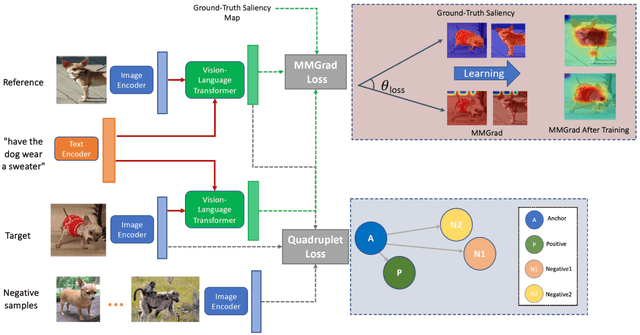
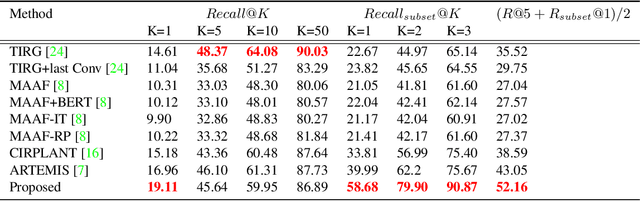
We consider the problem of composed image retrieval that takes an input query consisting of an image and a modification text indicating the desired changes to be made on the image and retrieves images that match these changes. Current state-of-the-art techniques that address this problem use global features for the retrieval, resulting in incorrect localization of the regions of interest to be modified because of the global nature of the features, more so in cases of real-world, in-the-wild images. Since modifier texts usually correspond to specific local changes in an image, it is critical that models learn local features to be able to both localize and retrieve better. To this end, our key novelty is a new gradient-attention-based learning objective that explicitly forces the model to focus on the local regions of interest being modified in each retrieval step. We achieve this by first proposing a new visual image attention computation technique, which we call multi-modal gradient attention (MMGrad) that is explicitly conditioned on the modifier text. We next demonstrate how MMGrad can be incorporated into an end-to-end model training strategy with a new learning objective that explicitly forces these MMGrad attention maps to highlight the correct local regions corresponding to the modifier text. By training retrieval models with this new loss function, we show improved grounding by means of better visual attention maps, leading to better explainability of the models as well as competitive quantitative retrieval performance on standard benchmark datasets.