 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end learning of keypoint detector and descriptor for pose invariant 3D matching
Paper and Code
May 09, 2018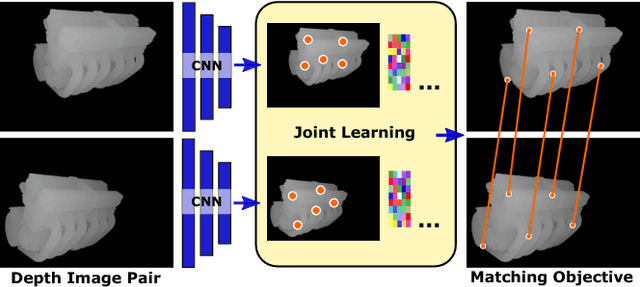
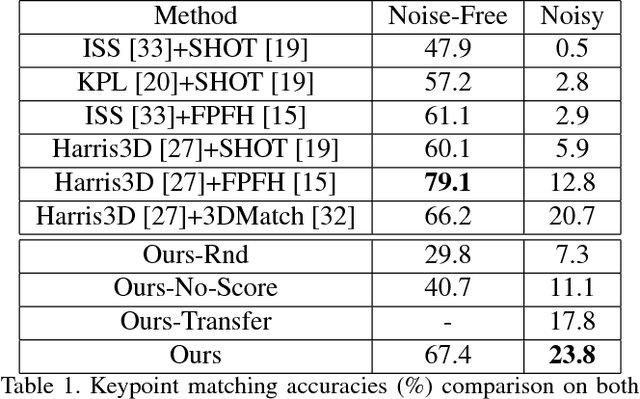
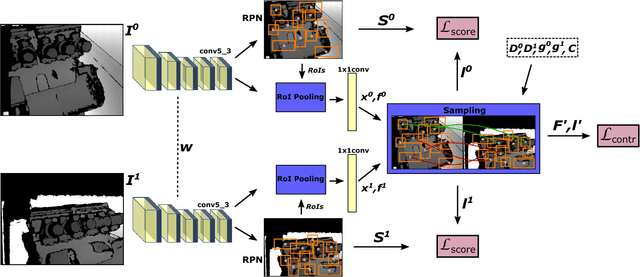
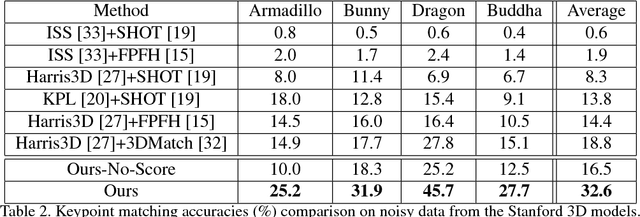
Finding correspondences between images or 3D scans is at the heart of many computer vision and image retrieval applications and is often enabled by matching local keypoint descriptors. Various learning approaches have been applied in the past to different stages of the matching pipeline, considering detector, descriptor, or metric learning objectives. These objectives were typically addressed separately and most previous work has focused on image data. This paper proposes an end-to-end learning framework for keypoint detection and its representation (descriptor) for 3D depth maps or 3D scans, where the two can be jointly optimized towards task-specific objectives without a need for separate annotations. We employ a Siamese architecture augmented by a sampling layer and a novel score loss function which in turn affects the selection of region proposals. The positive and negative examples are obtained automatically by sampling corresponding region proposals based on their consistency with known 3D pose labels. Matching experiments with depth data on multiple benchmark datasets demonstrate the efficacy of the proposed approach, showing significant improvements over state-of-the-art methods.