 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubtensor Quantization for Mobilenets
Nov 04, 2020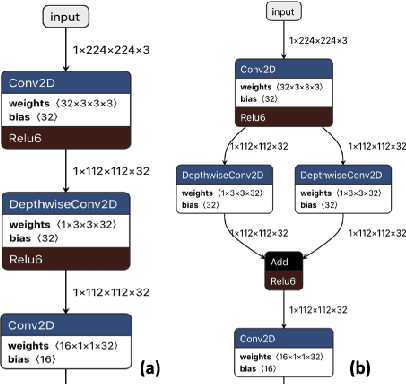
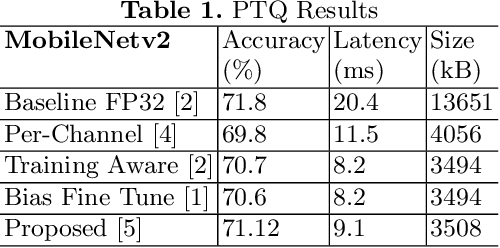
Quantization for deep neural networks (DNN) have enabled developers to deploy models with less memory and more efficient low-power inference. However, not all DNN designs are friendly to quantization. For example, the popular Mobilenet architecture has been tuned to reduce parameter size and computational latency with separable depth-wise convolutions, but not all quantization algorithms work well and the accuracy can suffer against its float point versions. In this paper, we analyzed several root causes of quantization loss and proposed alternatives that do not rely on per-channel or training-aware approaches. We evaluate the image classification task on ImageNet dataset, and our post-training quantized 8-bit inference top-1 accuracy in within 0.7% of the floating point version.