 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutcome-Guided Counterfactuals for Reinforcement Learning Agents from a Jointly Trained Generative Latent Space
Paper and Code
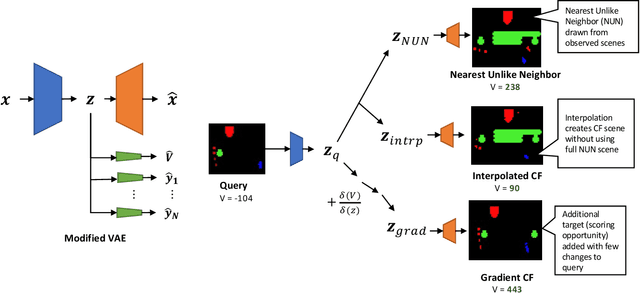
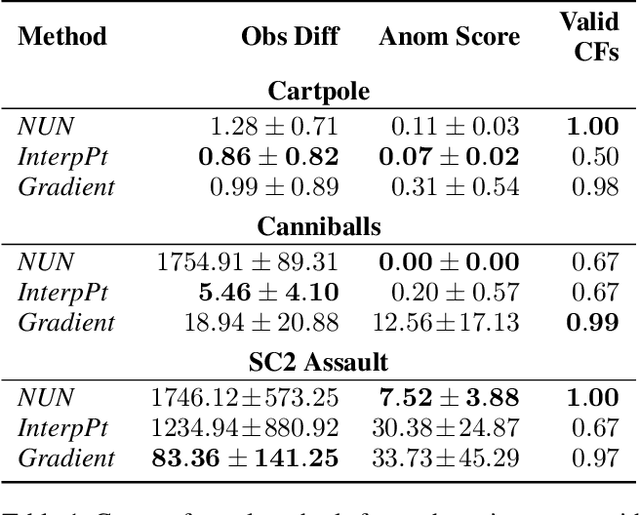
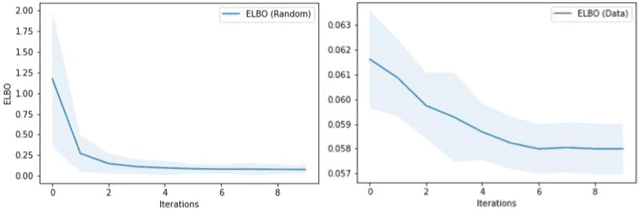
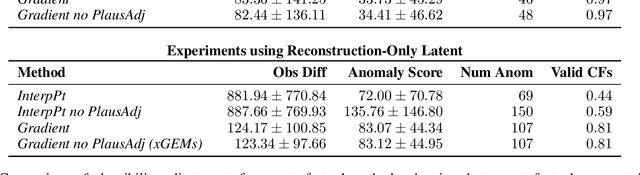
We present a novel generative method for producing unseen and plausible counterfactual examples for reinforcement learning (RL) agents based upon outcome variables that characterize agent behavior. Our approach uses a variational autoencoder to train a latent space that jointly encodes information about the observations and outcome variables pertaining to an agent's behavior. Counterfactuals are generated using traversals in this latent space, via gradient-driven updates as well as latent interpolations against cases drawn from a pool of examples. These include updates to raise the likelihood of generated examples, which improves the plausibility of generated counterfactuals. From experiments in three RL environments, we show that these methods produce counterfactuals that are more plausible and proximal to their queries compared to purely outcome-driven or case-based baselines. Finally, we show that a latent jointly trained to reconstruct both the input observations and behavioral outcome variables produces higher-quality counterfactuals over latents trained solely to reconstruct the observation inputs.