 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Tutor Discourse Supporting Rigorous Thinking with Tutee Content Mastery for Predicting Math Achievement
May 10, 2024This work investigates how tutoring discourse interacts with students' proximal knowledge to explain and predict students' learning outcomes. Our work is conducted in the context of high-dosage human tutoring where 9th-grade students (N= 1080) attended small group tutorials and individually practiced problems on an Intelligent Tutoring System (ITS). We analyzed whether tutors' talk moves and students' performance on the ITS predicted scores on math learning assessments. We trained Random Forest Classifiers (RFCs) to distinguish high and low assessment scores based on tutor talk moves, student's ITS performance metrics, and their combination. A decision tree was extracted from each RFC to yield an interpretable model. We found AUCs of 0.63 for talk moves, 0.66 for ITS, and 0.77 for their combination, suggesting interactivity among the two feature sources. Specifically, the best decision tree emerged from combining the tutor talk moves that encouraged rigorous thinking and students' ITS mastery. In essence, tutor talk that encouraged mathematical reasoning predicted achievement for students who demonstrated high mastery on the ITS, whereas tutors' revoicing of students' mathematical ideas and contributions was predictive for students with low ITS mastery. Implications for practice are discussed.
Bridging Declarative, Procedural, and Conditional Metacognitive Knowledge Gap Using Deep Reinforcement Learning
Apr 23, 2023



In deductive domains, three metacognitive knowledge types in ascending order are declarative, procedural, and conditional learning. This work leverages Deep Reinforcement Learning (DRL) in providing adaptive metacognitive interventions to bridge the gap between the three knowledge types and prepare students for future learning across Intelligent Tutoring Systems (ITSs). Students received these interventions that taught how and when to use a backward-chaining (BC) strategy on a logic tutor that supports a default forward-chaining strategy. Six weeks later, we trained students on a probability tutor that only supports BC without interventions. Our results show that on both ITSs, DRL bridged the metacognitive knowledge gap between students and significantly improved their learning performance over their control peers. Furthermore, the DRL policy adapted to the metacognitive development on the logic tutor across declarative, procedural, and conditional students, causing their strategic decisions to be more autonomous.
Leveraging Deep Reinforcement Learning for Metacognitive Interventions across Intelligent Tutoring Systems
Apr 17, 2023

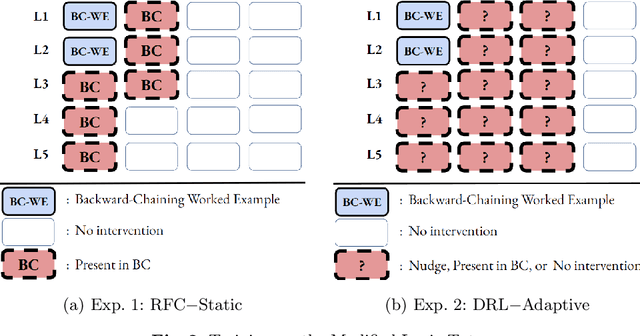

This work compares two approaches to provide metacognitive interventions and their impact on preparing students for future learning across Intelligent Tutoring Systems (ITSs). In two consecutive semesters, we conducted two classroom experiments: Exp. 1 used a classic artificial intelligence approach to classify students into different metacognitive groups and provide static interventions based on their classified groups. In Exp. 2, we leveraged Deep Reinforcement Learning (DRL) to provide adaptive interventions that consider the dynamic changes in the student's metacognitive levels. In both experiments, students received these interventions that taught how and when to use a backward-chaining (BC) strategy on a logic tutor that supports a default forward-chaining strategy. Six weeks later, we trained students on a probability tutor that only supports BC without interventions. Our results show that adaptive DRL-based interventions closed the metacognitive skills gap between students. In contrast, static classifier-based interventions only benefited a subset of students who knew how to use BC in advance. Additionally, our DRL agent prepared the experimental students for future learning by significantly surpassing their control peers on both ITSs.
Mixing Backward- with Forward-Chaining for Metacognitive Skill Acquisition and Transfer
Mar 18, 2023Metacognitive skills have been commonly associated with preparation for future learning in deductive domains. Many researchers have regarded strategy- and time-awareness as two metacognitive skills that address how and when to use a problem-solving strategy, respectively. It was shown that students who are both strategy-and time-aware (StrTime) outperformed their nonStrTime peers across deductive domains. In this work, students were trained on a logic tutor that supports a default forward-chaining (FC) and a backward-chaining (BC) strategy. We investigated the impact of mixing BC with FC on teaching strategy- and time-awareness for nonStrTime students. During the logic instruction, the experimental students (Exp) were provided with two BC worked examples and some problems in BC to practice how and when to use BC. Meanwhile, their control (Ctrl) and StrTime peers received no such intervention. Six weeks later, all students went through a probability tutor that only supports BC to evaluate whether the acquired metacognitive skills are transferred from logic. Our results show that on both tutors, Exp outperformed Ctrl and caught up with StrTime.
The Power of Nudging: Exploring Three Interventions for Metacognitive Skills Instruction across Intelligent Tutoring Systems
Mar 18, 2023



Deductive domains are typical of many cognitive skills in that no single problem-solving strategy is always optimal for solving all problems. It was shown that students who know how and when to use each strategy (StrTime) outperformed those who know neither and stick to the default strategy (Default). In this work, students were trained on a logic tutor that supports a default forward-chaining and a backward-chaining (BC) strategy, then a probability tutor that only supports BC. We investigated three types of interventions on teaching the Default students how and when to use which strategy on the logic tutor: Example, Nudge and Presented. Meanwhile, StrTime students received no interventions. Overall, our results show that Nudge outperformed their Default peers and caught up with StrTime on both tutors.
Investigating the Impact of Backward Strategy Learning in a Logic Tutor: Aiding Subgoal Learning towards Improved Problem Solving
Jul 27, 2022

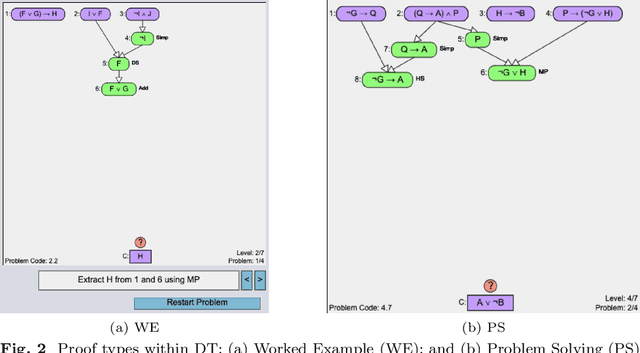
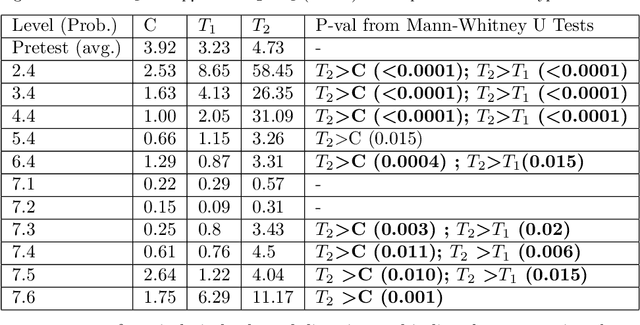
Learning to derive subgoals reduces the gap between experts and students and makes students prepared for future problem solving. Researchers have explored subgoal labeled instructional materials with explanations in traditional problem solving and within tutoring systems to help novices learn to subgoal. However, only a little research is found on problem-solving strategies in relationship with subgoal learning. Also, these strategies are under-explored within computer-based tutors and learning environments. Backward problem-solving strategy is closely related to the process of subgoaling, where problem solving iteratively refines the goal into a new subgoal to reduce difficulty. In this paper, we explore a training strategy for backward strategy learning within an intelligent logic tutor that teaches logic proof construction. The training session involved backward worked examples (BWE) and problem-solving (BPS) to help students learn backward strategy towards improving their subgoaling and problem-solving skills. To evaluate the training strategy, we analyzed students' 1) experience with and engagement in learning backward strategy, 2) performance, and 3) proof construction approaches in new problems that they solved independently without tutor help after each level of training and in post-test. Our results showed that, when new problems were given to solve without any tutor help, students who were trained with both BWE and BPS outperformed students who received none of the treatment or only BWE during training. Additionally, students trained with both BWE and BPS derived subgoals during proof construction with significantly higher efficiency than the other two groups.