 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Federated Learning via Synthetic Distiller-Distillate Communication
Paper and Code


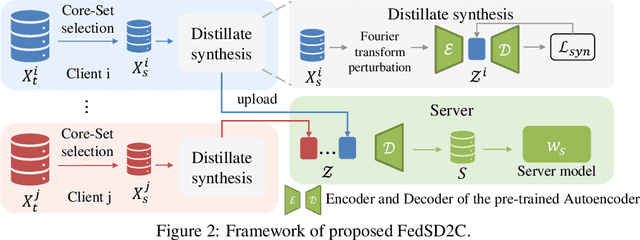

One-shot Federated learning (FL) is a powerful technology facilitating collaborative training of machine learning models in a single round of communication. While its superiority lies in communication efficiency and privacy preservation compared to iterative FL, one-shot FL often compromises model performance. Prior research has primarily focused on employing data-free knowledge distillation to optimize data generators and ensemble models for better aggregating local knowledge into the server model. However, these methods typically struggle with data heterogeneity, where inconsistent local data distributions can cause teachers to provide misleading knowledge. Additionally, they may encounter scalability issues with complex datasets due to inherent two-step information loss: first, during local training (from data to model), and second, when transferring knowledge to the server model (from model to inversed data). In this paper, we propose FedSD2C, a novel and practical one-shot FL framework designed to address these challenges. FedSD2C introduces a distiller to synthesize informative distillates directly from local data to reduce information loss and proposes sharing synthetic distillates instead of inconsistent local models to tackle data heterogeneity. Our empirical results demonstrate that FedSD2C consistently outperforms other one-shot FL methods with more complex and real datasets, achieving up to 2.6 the performance of the best baseline. Code: https://github.com/Carkham/FedSD2C