 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeminio: Language-Guided Gradient Inversion Attacks in Federated Learning
Nov 22, 2024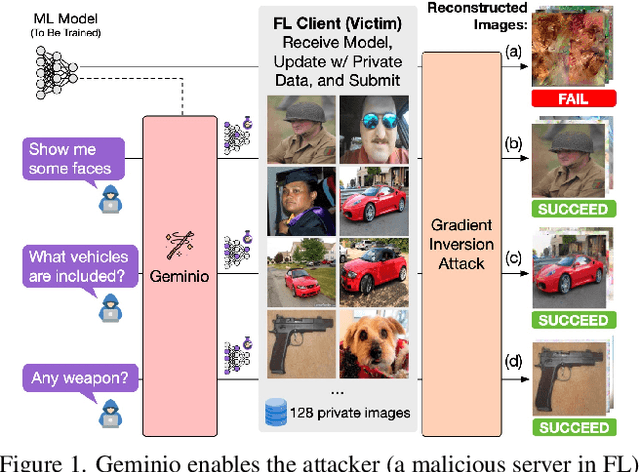

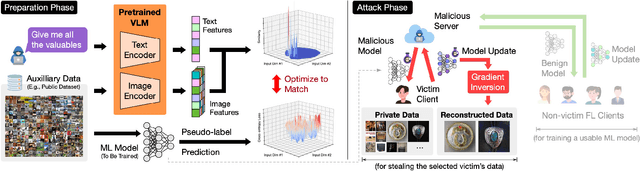
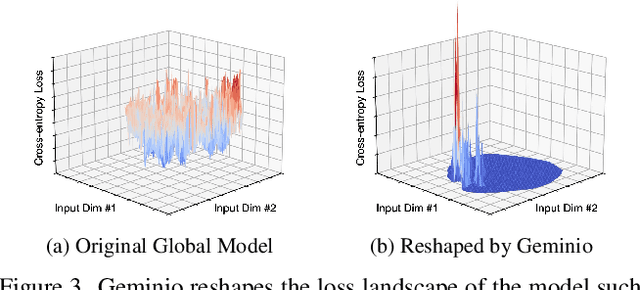
Foundation models that bridge vision and language have made significant progress, inspiring numerous life-enriching applications. However, their potential for misuse to introduce new threats remains largely unexplored. This paper reveals that vision-language models (VLMs) can be exploited to overcome longstanding limitations in gradient inversion attacks (GIAs) within federated learning (FL), where an FL server reconstructs private data samples from gradients shared by victim clients. Current GIAs face challenges in reconstructing high-resolution images, especially when the victim has a large local data batch. While focusing reconstruction on valuable samples rather than the entire batch is promising, existing methods lack the flexibility to allow attackers to specify their target data. In this paper, we introduce Geminio, the first approach to transform GIAs into semantically meaningful, targeted attacks. Geminio enables a brand new privacy attack experience: attackers can describe, in natural language, the types of data they consider valuable, and Geminio will prioritize reconstruction to focus on those high-value samples. This is achieved by leveraging a pretrained VLM to guide the optimization of a malicious global model that, when shared with and optimized by a victim, retains only gradients of samples that match the attacker-specified query. Extensive experiments demonstrate Geminio's effectiveness in pinpointing and reconstructing targeted samples, with high success rates across complex datasets under FL and large batch sizes and showing resilience against existing defenses.
AnywhereDoor: Multi-Target Backdoor Attacks on Object Detection
Nov 21, 2024



As object detection becomes integral to many safety-critical applications, understanding its vulnerabilities is essential. Backdoor attacks, in particular, pose a significant threat by implanting hidden backdoor in a victim model, which adversaries can later exploit to trigger malicious behaviors during inference. However, current backdoor techniques are limited to static scenarios where attackers must define a malicious objective before training, locking the attack into a predetermined action without inference-time adaptability. Given the expressive output space in object detection, including object existence detection, bounding box estimation, and object classification, the feasibility of implanting a backdoor that provides inference-time control with a high degree of freedom remains unexplored. This paper introduces AnywhereDoor, a flexible backdoor attack tailored for object detection. Once implanted, AnywhereDoor enables adversaries to specify different attack types (object vanishing, fabrication, or misclassification) and configurations (untargeted or targeted with specific classes) to dynamically control detection behavior. This flexibility is achieved through three key innovations: (i) objective disentanglement to support a broader range of attack combinations well beyond what existing methods allow; (ii) trigger mosaicking to ensure backdoor activations are robust, even against those object detectors that extract localized regions from the input image for recognition; and (iii) strategic batching to address object-level data imbalances that otherwise hinders a balanced manipulation. Extensive experiments demonstrate that AnywhereDoor provides attackers with a high degree of control, achieving an attack success rate improvement of nearly 80% compared to adaptations of existing methods for such flexible control.
Subgroup Discovery in Unstructured Data
Jul 15, 2022


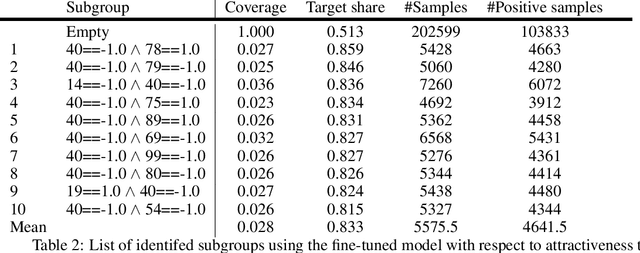
Subgroup discovery is a descriptive and exploratory data mining technique to identify subgroups in a population that exhibit interesting behavior with respect to a variable of interest. Subgroup discovery has numerous applications in knowledge discovery and hypothesis generation, yet it remains inapplicable for unstructured, high-dimensional data such as images. This is because subgroup discovery algorithms rely on defining descriptive rules based on (attribute, value) pairs, however, in unstructured data, an attribute is not well defined. Even in cases where the notion of attribute intuitively exists in the data, such as a pixel in an image, due to the high dimensionality of the data, these attributes are not informative enough to be used in a rule. In this paper, we introduce the subgroup-aware variational autoencoder, a novel variational autoencoder that learns a representation of unstructured data which leads to subgroups with higher quality. Our experimental results demonstrate the effectiveness of the method at learning subgroups with high quality while supporting the interpretability of the concepts.
An Interactive Visualization Tool for Understanding Active Learning
Nov 09, 2021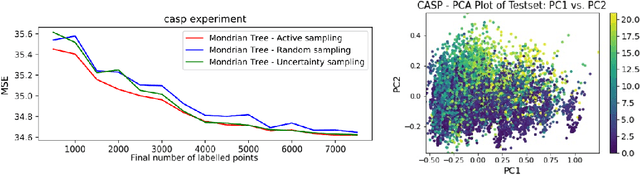
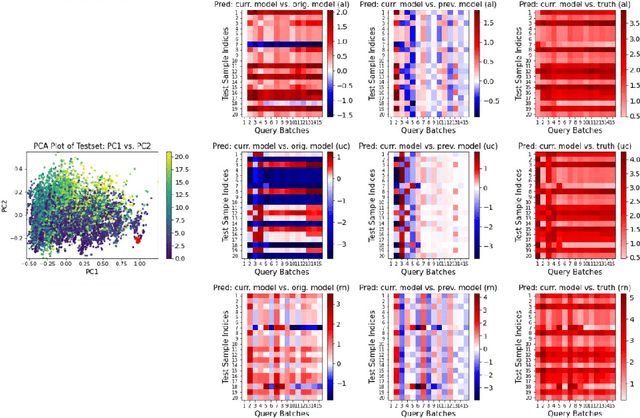
Despite recent progress in artificial intelligence and machine learning, many state-of-the-art methods suffer from a lack of explainability and transparency. The ability to interpret the predictions made by machine learning models and accurately evaluate these models is crucially important. In this paper, we present an interactive visualization tool to elucidate the training process of active learning. This tool enables one to select a sample of interesting data points, view how their prediction values change at different querying stages, and thus better understand when and how active learning works. Additionally, users can utilize this tool to compare different active learning strategies simultaneously and inspect why some strategies outperform others in certain contexts. With some preliminary experiments, we demonstrate that our visualization panel has a great potential to be used in various active learning experiments and help users evaluate their models appropriately.
An Active Approach for Model Interpretation
Oct 27, 2019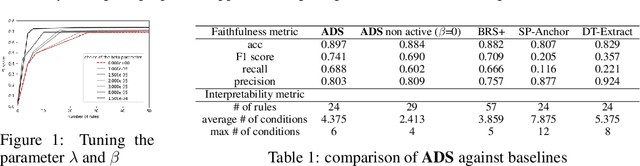

Model interpretation, or explanation of a machine learning classifier, aims to extract generalizable knowledge from a trained classifier into a human-understandable format, for various purposes such as model assessment, debugging and trust. From a computaional viewpoint, it is formulated as approximating the target classifier using a simpler interpretable model, such as rule models like a decision set/list/tree. Often, this approximation is handled as standard supervised learning and the only difference is that the labels are provided by the target classifier instead of ground truth. This paradigm is particularly popular because there exists a variety of well-studied supervised algorithms for learning an interpretable classifier. However, we argue that this paradigm is suboptimal for it does not utilize the unique property of the model interpretation problem, that is, the ability to generate synthetic instances and query the target classifier for their labels. We call this the active-query property, suggesting that we should consider model interpretation from an active learning perspective. Following this insight, we argue that the active-query property should be employed when designing a model interpretation algorithm, and that the generation of synthetic instances should be integrated seamlessly with the algorithm that learns the model interpretation. In this paper, we demonstrate that by doing so, it is possible to achieve more faithful interpretation with simpler model complexity. As a technical contribution, we present an active algorithm Active Decision Set Induction (ADS) to learn a decision set, a set of if-else rules, for model interpretation. ADS performs a local search over the space of all decision sets. In every iteration, ADS computes confidence intervals for the value of the objective function of all local actions and utilizes active-query to determine the best one.