 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cognitively-Inspired Neural Architecture for Visual Abstract Reasoning Using Contrastive Perceptual and Conceptual Processing
Sep 21, 2023



We introduce a new neural architecture for solving visual abstract reasoning tasks inspired by human cognition, specifically by observations that human abstract reasoning often interleaves perceptual and conceptual processing as part of a flexible, iterative, and dynamic cognitive process. Inspired by this principle, our architecture models visual abstract reasoning as an iterative, self-contrasting learning process that pursues consistency between perceptual and conceptual processing of visual stimuli. We explain how this new Contrastive Perceptual-Conceptual Network (CPCNet) works using matrix reasoning problems in the style of the well-known Raven's Progressive Matrices intelligence test. Experiments on the machine learning dataset RAVEN show that CPCNet achieves higher accuracy than all previously published models while also using the weakest inductive bias. We also point out a substantial and previously unremarked class imbalance in the original RAVEN dataset, and we propose a new variant of RAVEN -- AB-RAVEN -- that is more balanced in terms of abstract concepts.
A Computational Account Of Self-Supervised Visual Learning From Egocentric Object Play
May 30, 2023



Research in child development has shown that embodied experience handling physical objects contributes to many cognitive abilities, including visual learning. One characteristic of such experience is that the learner sees the same object from several different viewpoints. In this paper, we study how learning signals that equate different viewpoints -- e.g., assigning similar representations to different views of a single object -- can support robust visual learning. We use the Toybox dataset, which contains egocentric videos of humans manipulating different objects, and conduct experiments using a computer vision framework for self-supervised contrastive learning. We find that representations learned by equating different physical viewpoints of an object benefit downstream image classification accuracy. Further experiments show that this performance improvement is robust to variations in the gaps between viewpoints, and that the benefits transfer to several different image classification tasks.
Deep Non-Monotonic Reasoning for Visual Abstract Reasoning Tasks
Feb 08, 2023While achieving unmatched performance on many well-defined tasks, deep learning models have also been used to solve visual abstract reasoning tasks, which are relatively less well-defined, and have been widely used to measure human intelligence. However, current deep models struggle to match human abilities to solve such tasks with minimum data but maximum generalization. One limitation is that current deep learning models work in a monotonic way, i.e., treating different parts of the input in essentially fixed orderings, whereas people repeatedly observe and reason about the different parts of the visual stimuli until the reasoning process converges to a consistent conclusion, i.e., non-monotonic reasoning. This paper proposes a non-monotonic computational approach to solve visual abstract reasoning tasks. In particular, we implemented a deep learning model using this approach and tested it on the RAVEN dataset -- a dataset inspired by the Raven's Progressive Matrices test. Results show that the proposed approach is more effective than existing monotonic deep learning models, under strict experimental settings that represent a difficult variant of the RAVEN dataset problem.
Automatic Item Generation of Figural Analogy Problems: A Review and Outlook
Jan 20, 2022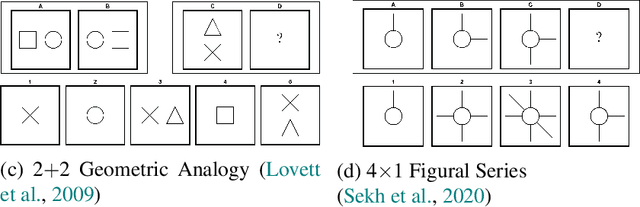
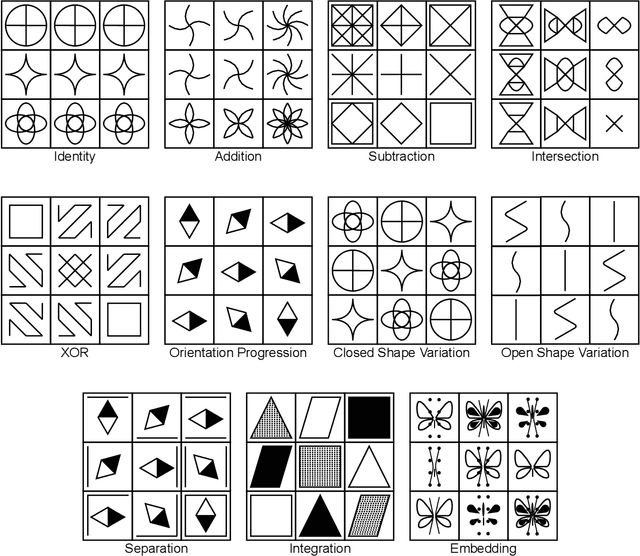
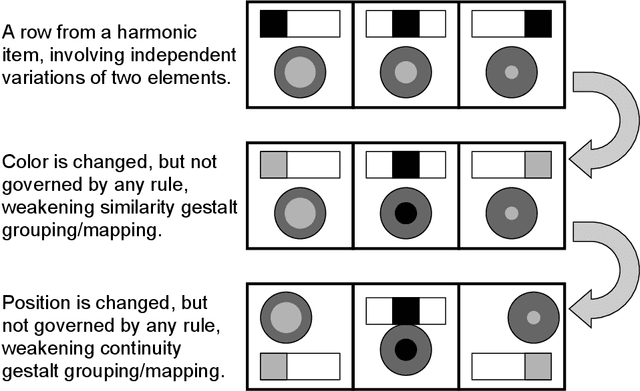
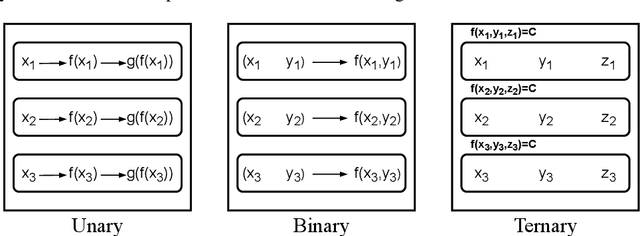
Figural analogy problems have long been a widely used format in human intelligence tests. In the past four decades, more and more research has investigated automatic item generation for figural analogy problems, i.e., algorithmic approaches for systematically and automatically creating such problems. In cognitive science and psychometrics, this research can deepen our understandings of human analogical ability and psychometric properties of figural analogies. With the recent development of data-driven AI models for reasoning about figural analogies, the territory of automatic item generation of figural analogies has further expanded. This expansion brings new challenges as well as opportunities, which demand reflection on previous item generation research and planning future studies. This paper reviews the important works of automatic item generation of figural analogies for both human intelligence tests and data-driven AI models. From an interdisciplinary perspective, the principles and technical details of these works are analyzed and compared, and desiderata for future research are suggested.
Variable-Viewpoint Representations for 3D Object Recognition
Feb 08, 2020
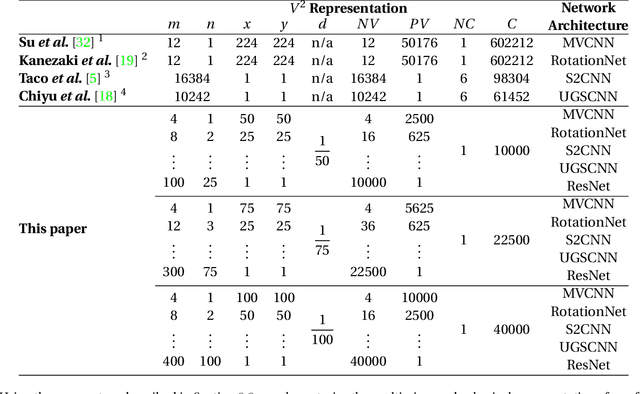

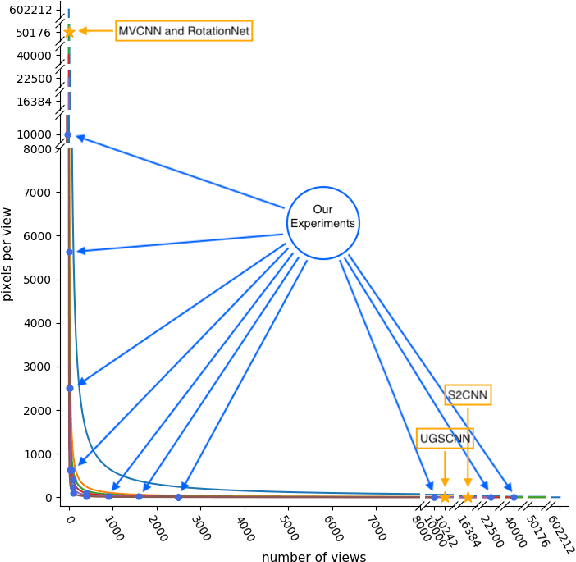
For the problem of 3D object recognition, researchers using deep learning methods have developed several very different input representations, including "multi-view" snapshots taken from discrete viewpoints around an object, as well as "spherical" representations consisting of a dense map of essentially ray-traced samples of the object from all directions. These representations offer trade-offs in terms of what object information is captured and to what degree of detail it is captured, but it is not clear how to measure these information trade-offs since the two types of representations are so different. We demonstrate that both types of representations in fact exist at two extremes of a common representational continuum, essentially choosing to prioritize either the number of views of an object or the pixels (i.e., field of view) allotted per view. We identify interesting intermediate representations that lie at points in between these two extremes, and we show, through systematic empirical experiments, how accuracy varies along this continuum as a function of input information as well as the particular deep learning architecture that is used.
Learning Spatially Structured Image Transformations Using Planar Neural Networks
Dec 03, 2019



Learning image transformations is essential to the idea of mental simulation as a method of cognitive inference. We take a connectionist modeling approach, using planar neural networks to learn fundamental imagery transformations, like translation, rotation, and scaling, from perceptual experiences in the form of image sequences. We investigate how variations in network topology, training data, and image shape, among other factors, affect the efficiency and effectiveness of learning visual imagery transformations, including effectiveness of transfer to operating on new types of data.