 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable-Viewpoint Representations for 3D Object Recognition
Paper and Code
Feb 08, 2020
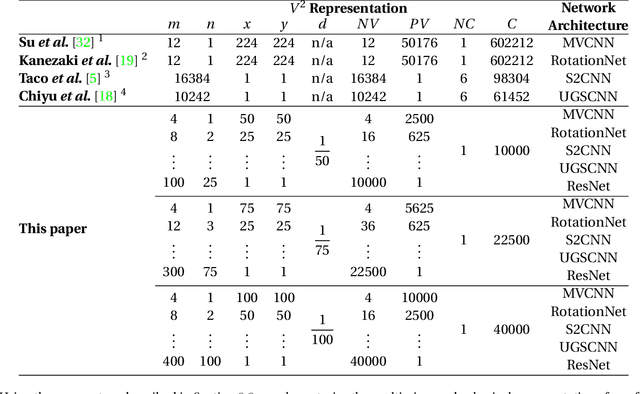

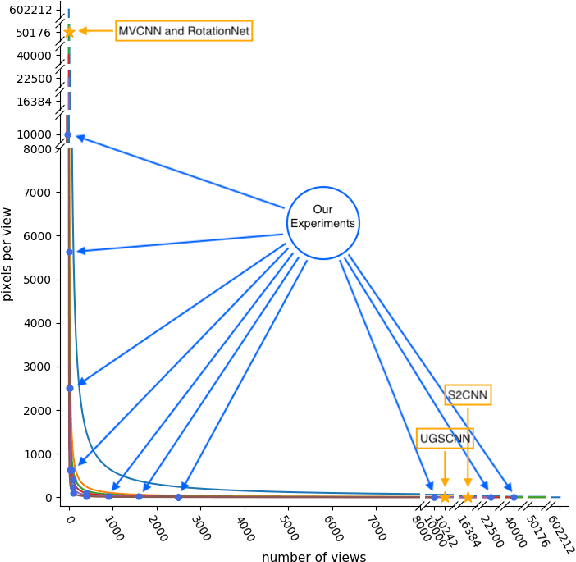
For the problem of 3D object recognition, researchers using deep learning methods have developed several very different input representations, including "multi-view" snapshots taken from discrete viewpoints around an object, as well as "spherical" representations consisting of a dense map of essentially ray-traced samples of the object from all directions. These representations offer trade-offs in terms of what object information is captured and to what degree of detail it is captured, but it is not clear how to measure these information trade-offs since the two types of representations are so different. We demonstrate that both types of representations in fact exist at two extremes of a common representational continuum, essentially choosing to prioritize either the number of views of an object or the pixels (i.e., field of view) allotted per view. We identify interesting intermediate representations that lie at points in between these two extremes, and we show, through systematic empirical experiments, how accuracy varies along this continuum as a function of input information as well as the particular deep learning architecture that is used.