 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Federated Learning with Model Caching on Mobile Agents
Paper and Code
Aug 26, 2024
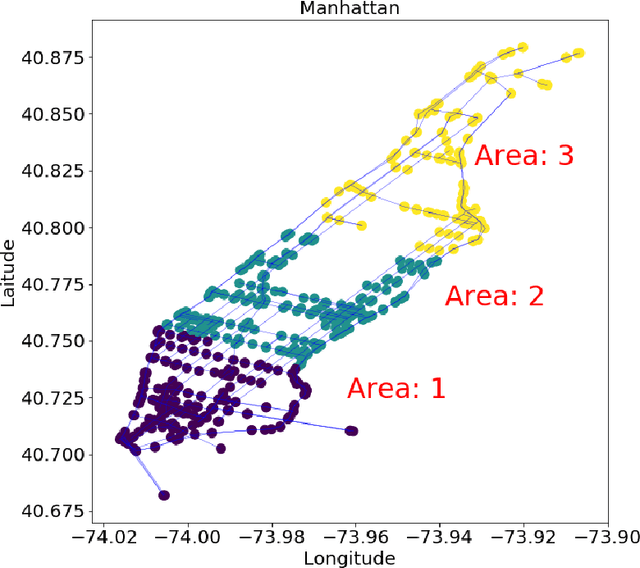
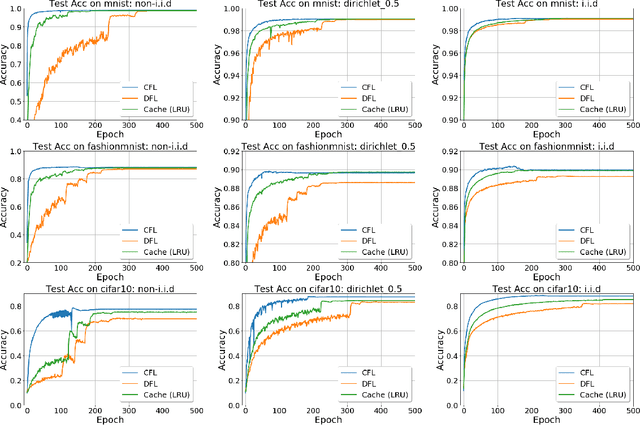
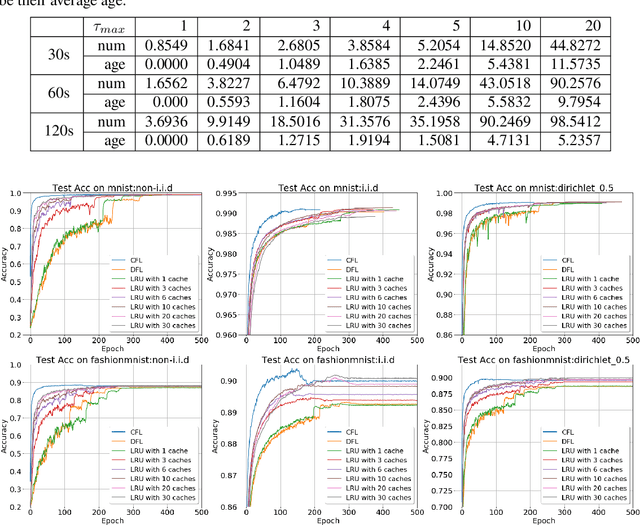
Federated Learning (FL) aims to train a shared model using data and computation power on distributed agents coordinated by a central server. Decentralized FL (DFL) utilizes local model exchange and aggregation between agents to reduce the communication and computation overheads on the central server. However, when agents are mobile, the communication opportunity between agents can be sporadic, largely hindering the convergence and accuracy of DFL. In this paper, we study delay-tolerant model spreading and aggregation enabled by model caching on mobile agents. Each agent stores not only its own model, but also models of agents encountered in the recent past. When two agents meet, they exchange their own models as well as the cached models. Local model aggregation works on all models in the cache. We theoretically analyze the convergence of DFL with cached models, explicitly taking into account the model staleness introduced by caching. We design and compare different model caching algorithms for different DFL and mobility scenarios. We conduct detailed case studies in a vehicular network to systematically investigate the interplay between agent mobility, cache staleness, and model convergence. In our experiments, cached DFL converges quickly, and significantly outperforms DFL without caching.