 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREMD: Crowd-Sourced Emotional Multimodal Dogs Dataset
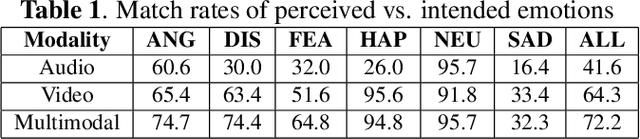
Feb 17, 2026Dog emotion recognition plays a crucial role in enhancing human-animal interactions, veterinary care, and the development of automated systems for monitoring canine well-being. However, accurately interpreting dog emotions is challenging due to the subjective nature of emotional assessments and the absence of standardized ground truth methods. We present the CREMD (Crowd-sourced Emotional Multimodal Dogs Dataset), a comprehensive dataset exploring how different presentation modes (e.g., context, audio, video) and annotator characteristics (e.g., dog ownership, gender, professional experience) influence the perception and labeling of dog emotions. The dataset consists of 923 video clips presented in three distinct modes: without context or audio, with context but no audio, and with both context and audio. We analyze annotations from diverse participants, including dog owners, professionals, and individuals with varying demographic backgrounds and experience levels, to identify factors that influence reliable dog emotion recognition. Our findings reveal several key insights: (1) while adding visual context significantly improved annotation agreement, our findings regarding audio cues are inconclusive due to design limitations (specifically, the absence of a no-context-with-audio condition and limited clean audio availability); (2) contrary to expectations, non-owners and male annotators showed higher agreement levels than dog owners and female annotators, respectively, while professionals showed higher agreement levels, aligned with our initial hypothesis; and (3) the presence of audio substantially increased annotators' confidence in identifying specific emotions, particularly anger and fear.
PID-Guided Partial Alignment for Multimodal Decentralized Federated Learning
Jan 15, 2026Multimodal decentralized federated learning (DFL) is challenging because agents differ in available modalities and model architectures, yet must collaborate over peer-to-peer (P2P) networks without a central coordinator. Standard multimodal pipelines learn a single shared embedding across all modalities. In DFL, such a monolithic representation induces gradient misalignment between uni- and multimodal agents; as a result, it suppresses heterogeneous sharing and cross-modal interaction. We present PARSE, a multimodal DFL framework that operationalizes partial information decomposition (PID) in a server-free setting. Each agent performs feature fission to factorize its latent representation into redundant, unique, and synergistic slices. P2P knowledge sharing among heterogeneous agents is enabled by slice-level partial alignment: only semantically shareable branches are exchanged among agents that possess the corresponding modality. By removing the need for central coordination and gradient surgery, PARSE resolves uni-/multimodal gradient conflicts, thereby overcoming the multimodal DFL dilemma while remaining compatible with standard DFL constraints. Across benchmarks and agent mixes, PARSE yields consistent gains over task-, modality-, and hybrid-sharing DFL baselines. Ablations on fusion operators and split ratios, together with qualitative visualizations, further demonstrate the efficiency and robustness of the proposed design.
CHUCKLE -- When Humans Teach AI To Learn Emotions The Easy Way
Oct 10, 2025
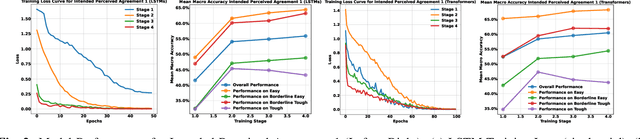
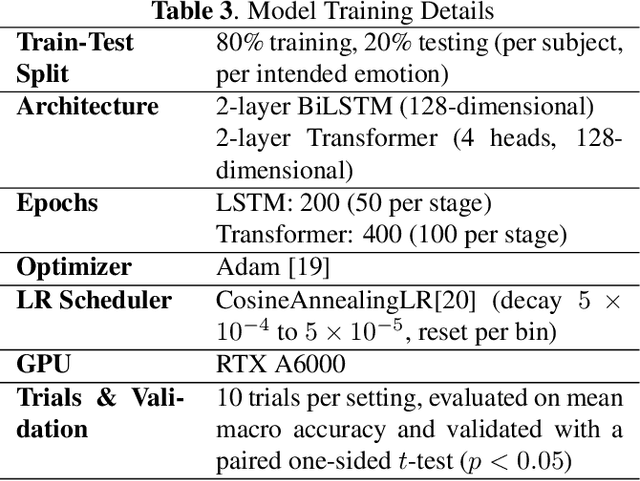
Curriculum learning (CL) structures training from simple to complex samples, facilitating progressive learning. However, existing CL approaches for emotion recognition often rely on heuristic, data-driven, or model-based definitions of sample difficulty, neglecting the difficulty for human perception, a critical factor in subjective tasks like emotion recognition. We propose CHUCKLE (Crowdsourced Human Understanding Curriculum for Knowledge Led Emotion Recognition), a perception-driven CL framework that leverages annotator agreement and alignment in crowd-sourced datasets to define sample difficulty, under the assumption that clips challenging for humans are similarly hard for machine learning models. Empirical results suggest that CHUCKLE increases the relative mean accuracy by 6.56% for LSTMs and 1.61% for Transformers over non-curriculum baselines, while reducing the number of gradient updates, thereby enhancing both training efficiency and model robustness.
Decentralized Federated Learning with Model Caching on Mobile Agents
Aug 26, 2024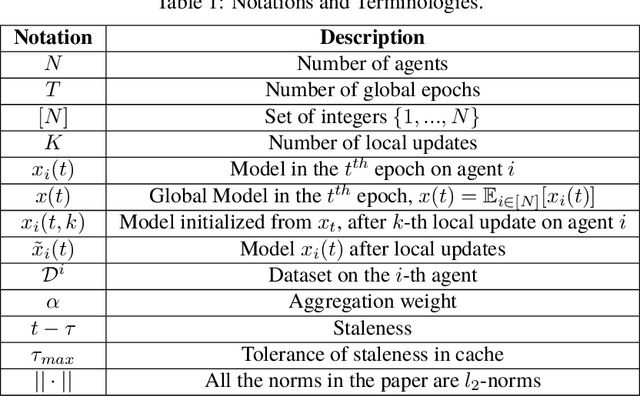
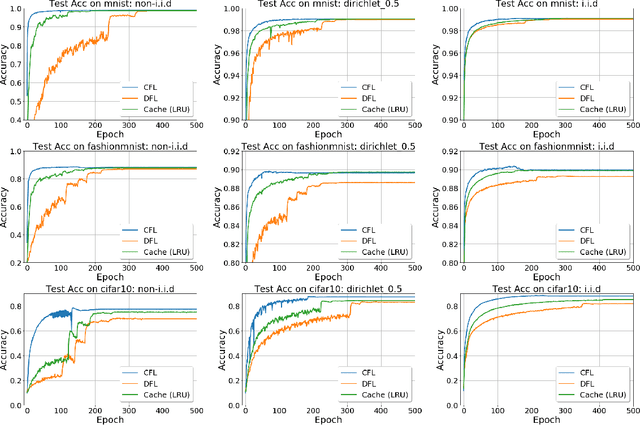
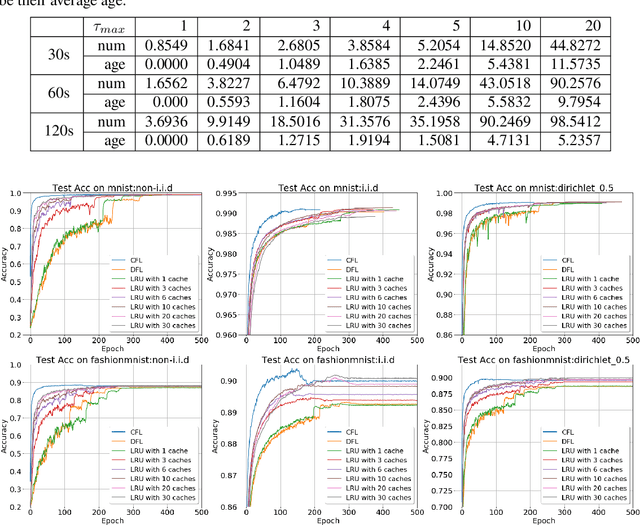
Federated Learning (FL) aims to train a shared model using data and computation power on distributed agents coordinated by a central server. Decentralized FL (DFL) utilizes local model exchange and aggregation between agents to reduce the communication and computation overheads on the central server. However, when agents are mobile, the communication opportunity between agents can be sporadic, largely hindering the convergence and accuracy of DFL. In this paper, we study delay-tolerant model spreading and aggregation enabled by model caching on mobile agents. Each agent stores not only its own model, but also models of agents encountered in the recent past. When two agents meet, they exchange their own models as well as the cached models. Local model aggregation works on all models in the cache. We theoretically analyze the convergence of DFL with cached models, explicitly taking into account the model staleness introduced by caching. We design and compare different model caching algorithms for different DFL and mobility scenarios. We conduct detailed case studies in a vehicular network to systematically investigate the interplay between agent mobility, cache staleness, and model convergence. In our experiments, cached DFL converges quickly, and significantly outperforms DFL without caching.
Predictive Edge Caching through Deep Mining of Sequential Patterns in User Content Retrievals
Oct 06, 2022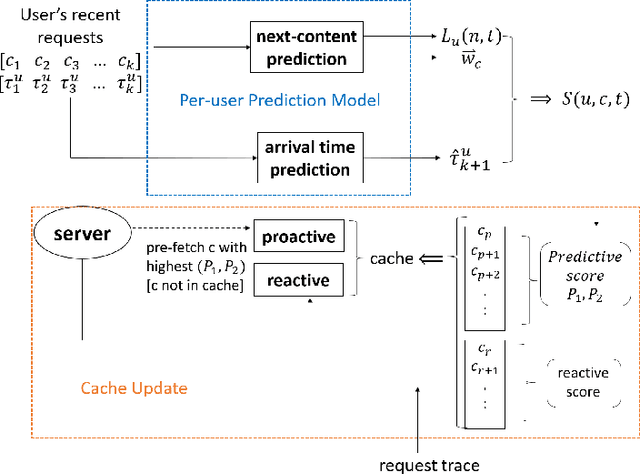
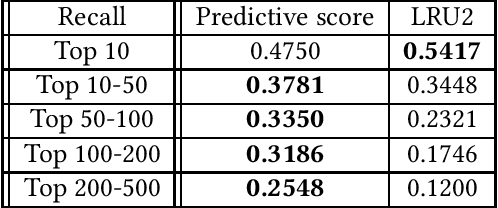
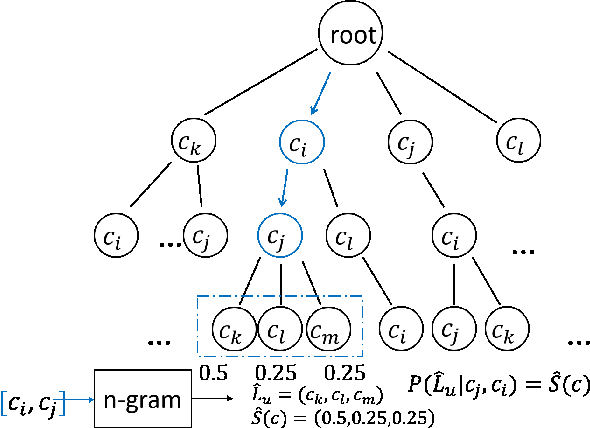
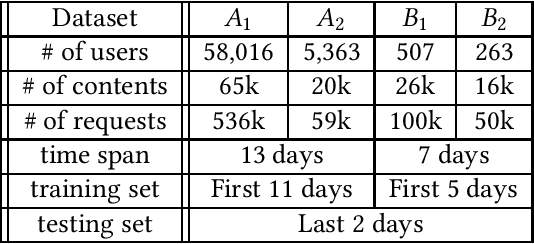
Edge caching plays an increasingly important role in boosting user content retrieval performance while reducing redundant network traffic. The effectiveness of caching ultimately hinges on the accuracy of predicting content popularity in the near future. However, at the network edge, content popularity can be extremely dynamic due to diverse user content retrieval behaviors and the low-degree of user multiplexing. It's challenging for the traditional reactive caching systems to keep up with the dynamic content popularity patterns. In this paper, we propose a novel Predictive Edge Caching (PEC) system that predicts the future content popularity using fine-grained learning models that mine sequential patterns in user content retrieval behaviors, and opportunistically prefetches contents predicted to be popular in the near future using idle network bandwidth. Through extensive experiments driven by real content retrieval traces, we demonstrate that PEC can adapt to highly dynamic content popularity, and significantly improve cache hit ratio and reduce user content retrieval latency over the state-of-art caching policies. More broadly, our study demonstrates that edge caching performance can be boosted by deep mining of user content retrieval behaviors.
Attention-based Region of Interest (ROI) Detection for Speech Emotion Recognition
Mar 03, 2022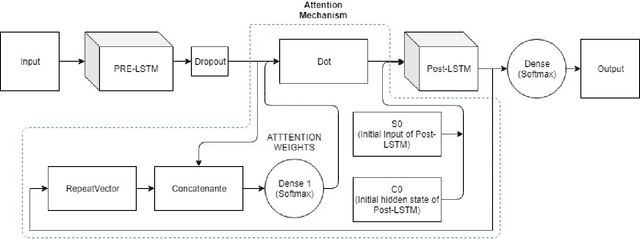
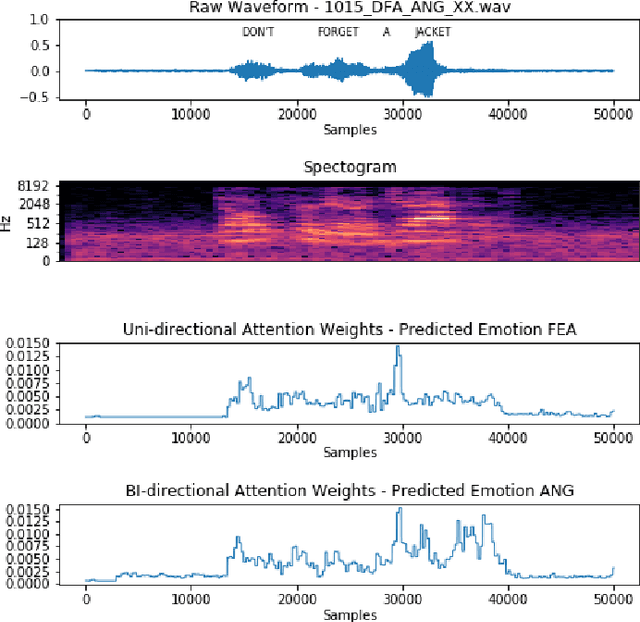

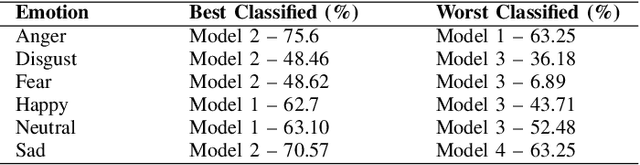
Automatic emotion recognition for real-life appli-cations is a challenging task. Human emotion expressions aresubtle, and can be conveyed by a combination of several emo-tions. In most existing emotion recognition studies, each audioutterance/video clip is labelled/classified in its entirety. However,utterance/clip-level labelling and classification can be too coarseto capture the subtle intra-utterance/clip temporal dynamics. Forexample, an utterance/video clip usually contains only a fewemotion-salient regions and many emotionless regions. In thisstudy, we propose to use attention mechanism in deep recurrentneural networks to detection the Regions-of-Interest (ROI) thatare more emotionally salient in human emotional speech/video,and further estimate the temporal emotion dynamics by aggre-gating those emotionally salient regions-of-interest. We comparethe ROI from audio and video and analyse them. We comparethe performance of the proposed attention networks with thestate-of-the-art LSTM models on multi-class classification task ofrecognizing six basic human emotions, and the proposed attentionmodels exhibit significantly better performance. Furthermore, theattention weight distribution can be used to interpret how anutterance can be expressed as a mixture of possible emotions.
Realtime Mobile Bandwidth and Handoff Predictions in 4G/5G Networks
Apr 27, 2021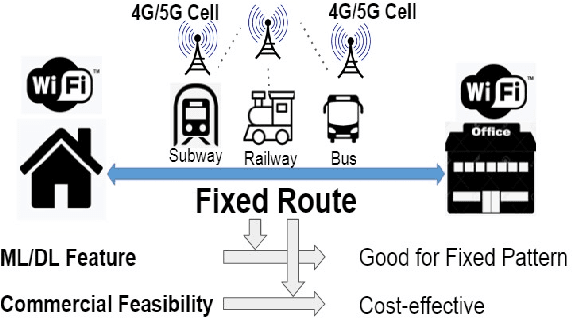
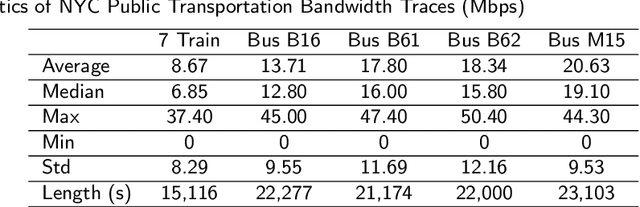

Mobile apps are increasingly relying on high-throughput and low-latency content delivery, while the available bandwidth on wireless access links is inherently time-varying. The handoffs between base stations and access modes due to user mobility present additional challenges to deliver a high level of user Quality-of-Experience (QoE). The ability to predict the available bandwidth and the upcoming handoffs will give applications valuable leeway to make proactive adjustments to avoid significant QoE degradation. In this paper, we explore the possibility and accuracy of realtime mobile bandwidth and handoff predictions in 4G/LTE and 5G networks. Towards this goal, we collect long consecutive traces with rich bandwidth, channel, and context information from public transportation systems. We develop Recurrent Neural Network models to mine the temporal patterns of bandwidth evolution in fixed-route mobility scenarios. Our models consistently outperform the conventional univariate and multivariate bandwidth prediction models. For 4G \& 5G co-existing networks, we propose a new problem of handoff prediction between 4G and 5G, which is important for low-latency applications like self-driving strategy in realistic 5G scenarios. We develop classification and regression based prediction models, which achieve more than 80\% accuracy in predicting 4G and 5G handoffs in a recent 5G dataset.
Cocktail Edge Caching: Ride Dynamic Trends of Content Popularity with Ensemble Learning
Jan 14, 2021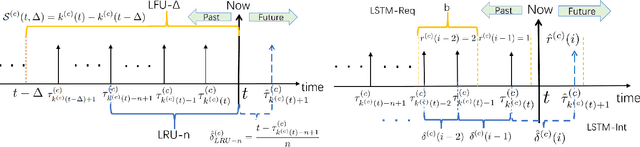
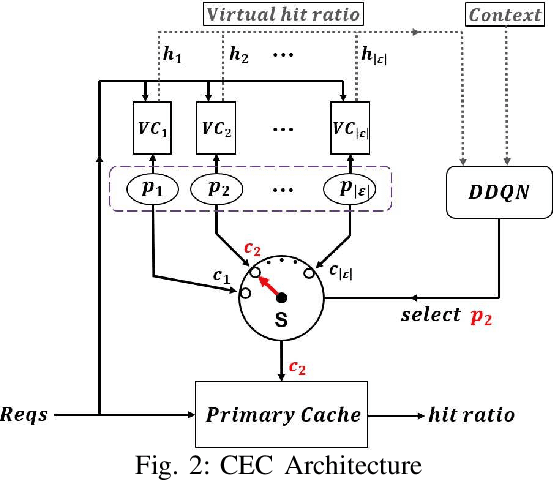
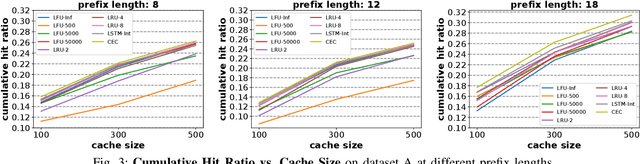
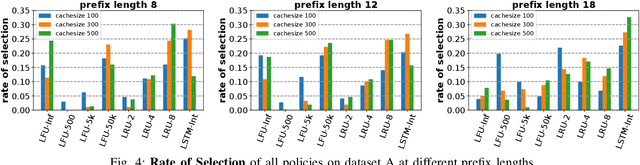
Edge caching will play a critical role in facilitating the emerging content-rich applications. However, it faces many new challenges, in particular, the highly dynamic content popularity and the heterogeneous caching configurations. In this paper, we propose Cocktail Edge Caching, that tackles the dynamic popularity and heterogeneity through ensemble learning. Instead of trying to find a single dominating caching policy for all the caching scenarios, we employ an ensemble of constituent caching policies and adaptively select the best-performing policy to control the cache. Towards this goal, we first show through formal analysis and experiments that different variations of the LFU and LRU policies have complementary performance in different caching scenarios. We further develop a novel caching algorithm that enhances LFU/LRU with deep recurrent neural network (LSTM) based time-series analysis. Finally, we develop a deep reinforcement learning agent that adaptively combines base caching policies according to their virtual hit ratios on parallel virtual caches. Through extensive experiments driven by real content requests from two large video streaming platforms, we demonstrate that CEC not only consistently outperforms all single policies, but also improves the robustness of them. CEC can be well generalized to different caching scenarios with low computation overheads for deployment.