 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor-Quality Invariance for Robust Medical Image Segmentation
Feb 11, 2025Single-source domain generalization (SDG) in medical image segmentation remains a significant challenge, particularly for images with varying color distributions and qualities. Previous approaches often struggle when models trained on high-quality images fail to generalize to low-quality test images due to these color and quality shifts. In this work, we propose two novel techniques to enhance generalization: dynamic color image normalization (DCIN) module and color-quality generalization (CQG) loss. The DCIN dynamically normalizes the color of test images using two reference image selection strategies. Specifically, the DCIN utilizes a global reference image selection (GRIS), which finds a universal reference image, and a local reference image selection (LRIS), which selects a semantically similar reference image per test sample. Additionally, CQG loss enforces invariance to color and quality variations by ensuring consistent segmentation predictions across transformed image pairs. Experimental results show that our proposals significantly improve segmentation performance over the baseline on two target domain datasets, despite being trained solely on a single source domain. Notably, our model achieved up to a 32.3-point increase in Dice score compared to the baseline, consistently producing robust and usable results even under substantial domain shifts. Our work contributes to the development of more robust medical image segmentation models that generalize across unseen domains. The implementation code is available at https://github.com/RaviShah1/DCIN-CQG.
Attention-based Region of Interest (ROI) Detection for Speech Emotion Recognition
Mar 03, 2022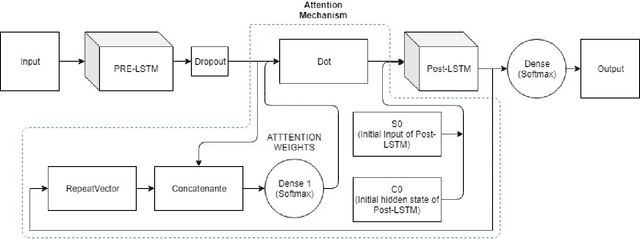
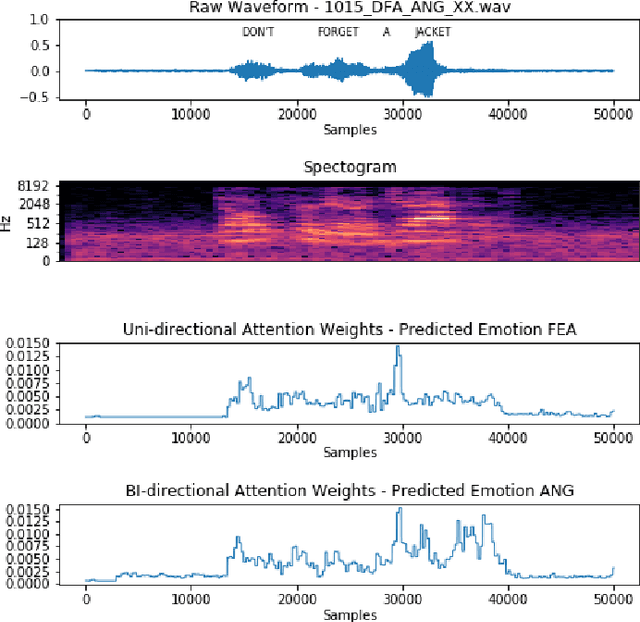

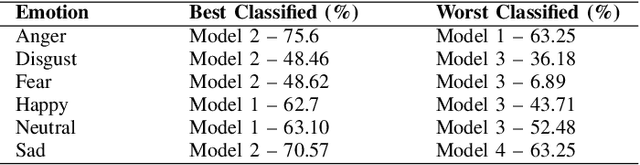
Automatic emotion recognition for real-life appli-cations is a challenging task. Human emotion expressions aresubtle, and can be conveyed by a combination of several emo-tions. In most existing emotion recognition studies, each audioutterance/video clip is labelled/classified in its entirety. However,utterance/clip-level labelling and classification can be too coarseto capture the subtle intra-utterance/clip temporal dynamics. Forexample, an utterance/video clip usually contains only a fewemotion-salient regions and many emotionless regions. In thisstudy, we propose to use attention mechanism in deep recurrentneural networks to detection the Regions-of-Interest (ROI) thatare more emotionally salient in human emotional speech/video,and further estimate the temporal emotion dynamics by aggre-gating those emotionally salient regions-of-interest. We comparethe ROI from audio and video and analyse them. We comparethe performance of the proposed attention networks with thestate-of-the-art LSTM models on multi-class classification task ofrecognizing six basic human emotions, and the proposed attentionmodels exhibit significantly better performance. Furthermore, theattention weight distribution can be used to interpret how anutterance can be expressed as a mixture of possible emotions.