 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor-Quality Invariance for Robust Medical Image Segmentation
Feb 11, 2025Single-source domain generalization (SDG) in medical image segmentation remains a significant challenge, particularly for images with varying color distributions and qualities. Previous approaches often struggle when models trained on high-quality images fail to generalize to low-quality test images due to these color and quality shifts. In this work, we propose two novel techniques to enhance generalization: dynamic color image normalization (DCIN) module and color-quality generalization (CQG) loss. The DCIN dynamically normalizes the color of test images using two reference image selection strategies. Specifically, the DCIN utilizes a global reference image selection (GRIS), which finds a universal reference image, and a local reference image selection (LRIS), which selects a semantically similar reference image per test sample. Additionally, CQG loss enforces invariance to color and quality variations by ensuring consistent segmentation predictions across transformed image pairs. Experimental results show that our proposals significantly improve segmentation performance over the baseline on two target domain datasets, despite being trained solely on a single source domain. Notably, our model achieved up to a 32.3-point increase in Dice score compared to the baseline, consistently producing robust and usable results even under substantial domain shifts. Our work contributes to the development of more robust medical image segmentation models that generalize across unseen domains. The implementation code is available at https://github.com/RaviShah1/DCIN-CQG.
From Brainwaves to Brain Scans: A Robust Neural Network for EEG-to-fMRI Synthesis
Feb 11, 2025While functional magnetic resonance imaging (fMRI) offers rich spatial resolution, it is limited by high operational costs and significant infrastructural demands. In contrast, electroencephalography (EEG) provides millisecond-level precision in capturing electrical activity but lacks the spatial resolution necessary for precise neural localization. To bridge these gaps, we introduce E2fNet, a simple yet effective deep learning model for synthesizing fMRI images from low-cost EEG data. E2fNet is specifically designed to capture and translate meaningful features from EEG across electrode channels into accurate fMRI representations. Extensive evaluations across three datasets demonstrate that E2fNet consistently outperforms existing methods, achieving state-of-the-art results in terms of the structural similarity index measure (SSIM). Our findings suggest that E2fNet is a promising, cost-effective solution for enhancing neuroimaging capabilities. The code is available at https://github.com/kgr20/E2fNet.
High-Quality Medical Image Generation from Free-hand Sketch
Feb 01, 2024Generating medical images from human-drawn free-hand sketches holds promise for various important medical imaging applications. Due to the extreme difficulty in collecting free-hand sketch data in the medical domain, most deep learning-based methods have been proposed to generate medical images from the synthesized sketches (e.g., edge maps or contours of segmentation masks from real images). However, these models often fail to generalize on the free-hand sketches, leading to unsatisfactory results. In this paper, we propose a practical free-hand sketch-to-image generation model called Sketch2MedI that learns to represent sketches in StyleGAN's latent space and generate medical images from it. Thanks to the ability to encode sketches into this meaningful representation space, Sketch2MedI only requires synthesized sketches for training, enabling a cost-effective learning process. Our Sketch2MedI demonstrates a robust generalization to free-hand sketches, resulting in high-quality and realistic medical image generations. Comparative evaluations of Sketch2MedI against the pix2pix, CycleGAN, UNIT, and U-GAT-IT models show superior performance in generating pharyngeal images, both quantitative and qualitative across various metrics.
Towards Robust Plant Disease Diagnosis with Hard-sample Re-mining Strategy
Sep 05, 2023



With rich annotation information, object detection-based automated plant disease diagnosis systems (e.g., YOLO-based systems) often provide advantages over classification-based systems (e.g., EfficientNet-based), such as the ability to detect disease locations and superior classification performance. One drawback of these detection systems is dealing with unannotated healthy data with no real symptoms present. In practice, healthy plant data appear to be very similar to many disease data. Thus, those models often produce mis-detected boxes on healthy images. In addition, labeling new data for detection models is typically time-consuming. Hard-sample mining (HSM) is a common technique for re-training a model by using the mis-detected boxes as new training samples. However, blindly selecting an arbitrary amount of hard-sample for re-training will result in the degradation of diagnostic performance for other diseases due to the high similarity between disease and healthy data. In this paper, we propose a simple but effective training strategy called hard-sample re-mining (HSReM), which is designed to enhance the diagnostic performance of healthy data and simultaneously improve the performance of disease data by strategically selecting hard-sample training images at an appropriate level. Experiments based on two practical in-field eight-class cucumber and ten-class tomato datasets (42.7K and 35.6K images) show that our HSReM training strategy leads to a substantial improvement in the overall diagnostic performance on large-scale unseen data. Specifically, the object detection model trained using the HSReM strategy not only achieved superior results as compared to the classification-based state-of-the-art EfficientNetV2-Large model and the original object detection model, but also outperformed the model using the HSM strategy.
A Practical Framework for Unsupervised Structure Preservation Medical Image Enhancement
Apr 04, 2023Medical images are extremely valuable for supporting medical diagnoses. However, in practice, low-quality (LQ) medical images, such as images that are hazy/blurry, have uneven illumination, or are out of focus, among others, are often obtained during data acquisition. This leads to difficulties in the screening and diagnosis of medical diseases. Several generative adversarial networks (GAN)-based image enhancement methods have been proposed and have shown promising results. However, there is a quality-originality trade-off among these methods in the sense that they produce visually pleasing results but lose the ability to preserve originality, especially the structural inputs. Moreover, to our knowledge, there is no objective metric in evaluating the structure preservation of medical image enhancement methods in unsupervised settings due to the unavailability of paired ground-truth data. In this study, we propose a framework for practical unsupervised medical image enhancement that includes (1) a non-reference objective evaluation of structure preservation for medical image enhancement tasks called Laplacian structural similarity index measure (LaSSIM), which is based on SSIM and the Laplacian pyramid, and (2) a novel unsupervised GAN-based method called Laplacian medical image enhancement (LaMEGAN) to support the improvement of both originality and quality from LQ images. The LaSSIM metric does not require clean reference images and has been shown to be superior to SSIM in capturing image structural changes under image degradations, such as strong blurring on different datasets. The experiments demonstrated that our LaMEGAN achieves a satisfactory balance between quality and originality, with robust structure preservation performance while generating compelling visual results with very high image quality scores. The code will be made available at https://github.com/AillisInc/USPMIE.
MIINet: An Image Quality Improvement Framework for Supporting Medical Diagnosis
Nov 28, 2020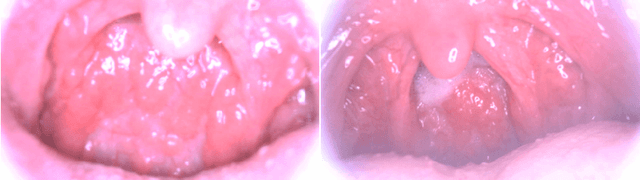
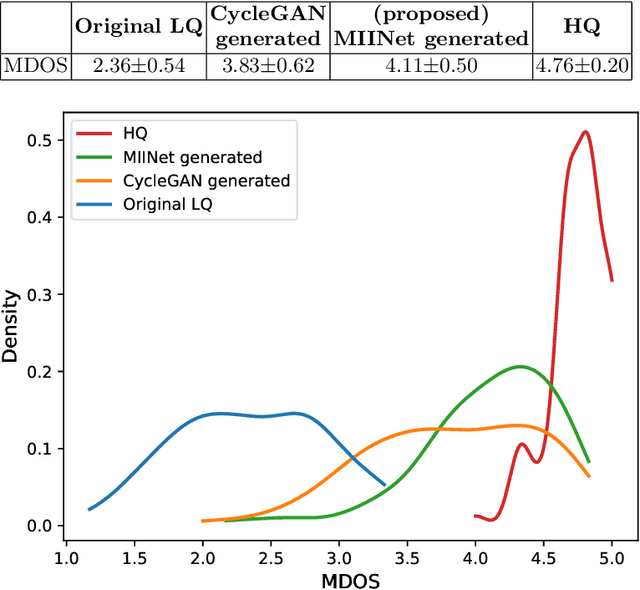

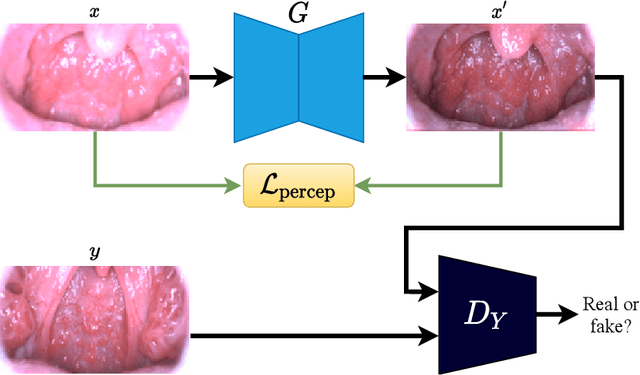
Medical images have been indispensable and useful tools for supporting medical experts in making diagnostic decisions. However, taken medical images especially throat and endoscopy images are normally hazy, lack of focus, or uneven illumination. Thus, these could difficult the diagnosis process for doctors. In this paper, we propose MIINet, a novel image-to-image translation network for improving quality of medical images by unsupervised translating low-quality images to the high-quality clean version. Our MIINet is not only capable of generating high-resolution clean images, but also preserving the attributes of original images, making the diagnostic more favorable for doctors. Experiments on dehazing 100 practical throat images show that our MIINet largely improves the mean doctor opinion score (MDOS), which assesses the quality and the reproducibility of the images from the baseline of 2.36 to 4.11, while dehazed images by CycleGAN got lower score of 3.83. The MIINet is confirmed by three physicians to be satisfying in supporting throat disease diagnostic from original low-quality images.
Detection of Collision-Prone Vehicle Behavior at Intersections using Siamese Interaction LSTM
Dec 10, 2019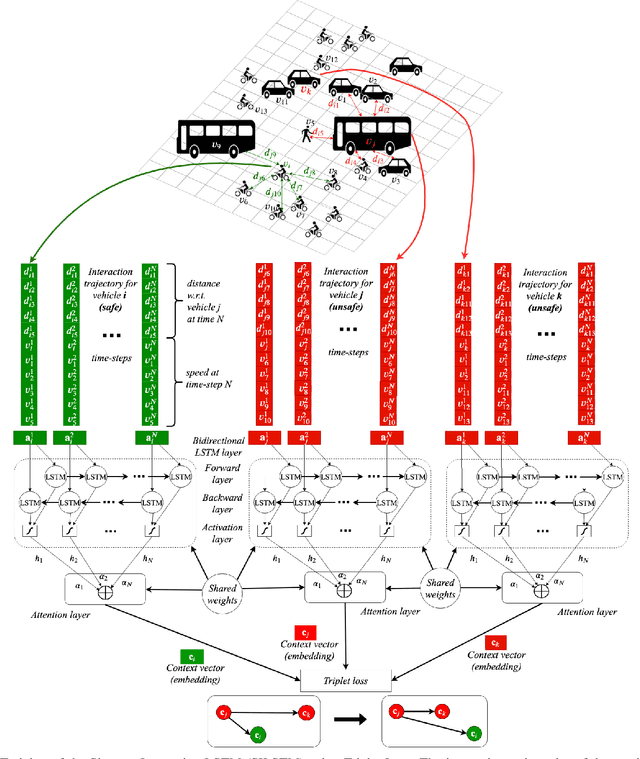

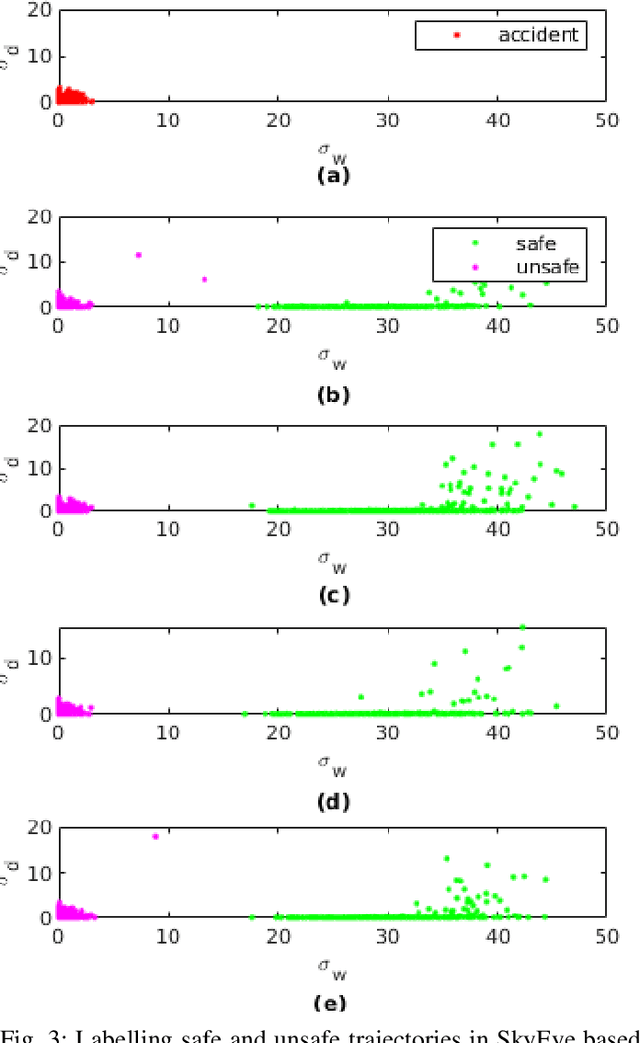
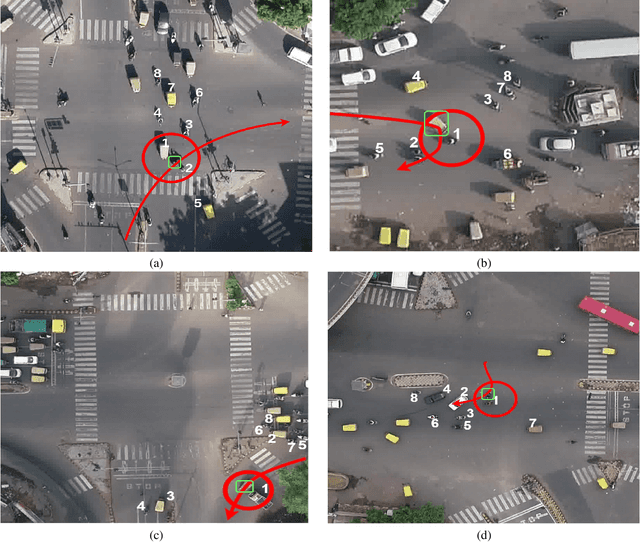
As a large proportion of road accidents occur at intersections, monitoring traffic safety of intersections is important. Existing approaches are designed to investigate accidents in lane-based traffic. However, such approaches are not suitable in a lane-less mixed-traffic environment where vehicles often ply very close to each other. Hence, we propose an approach called Siamese Interaction Long Short-Term Memory network (SILSTM) to detect collision prone vehicle behavior. The SILSTM network learns the interaction trajectory of a vehicle that describes the interactions of a vehicle with its neighbors at an intersection. Among the hundreds of interactions for every vehicle, there maybe only some interactions which may be unsafe and hence, a temporal attention layer is used in the SILSTM network. Furthermore, the comparison of interaction trajectories requires labeling the trajectories as either unsafe or safe, but such a distinction is highly subjective, especially in lane-less traffic. Hence, in this work, we compute the characteristics of interaction trajectories involved in accidents using the collision energy model. The interaction trajectories that match accident characteristics are labeled as unsafe while the rest are considered safe. Finally, there is no existing dataset that allows us to monitor a particular intersection for a long duration. Therefore, we introduce the SkyEye dataset that contains 1 hour of continuous aerial footage from each of the 4 chosen intersections in the city of Ahmedabad in India. A detailed evaluation of SILSTM on the SkyEye dataset shows that unsafe (collision-prone) interaction trajectories can be effectively detected at different intersections.