 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposal Distribution Calibration for Few-Shot Object Detection
Dec 15, 2022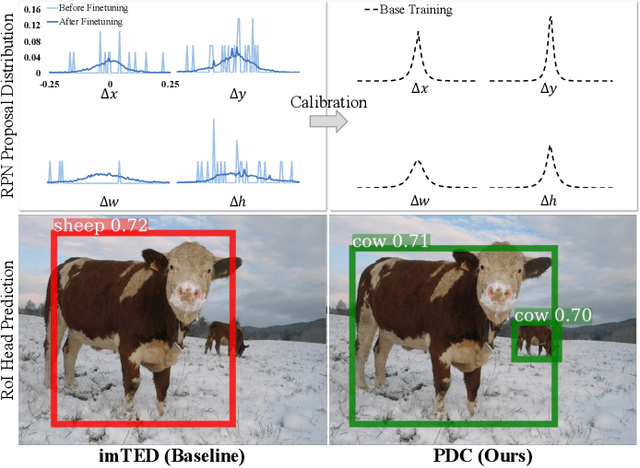
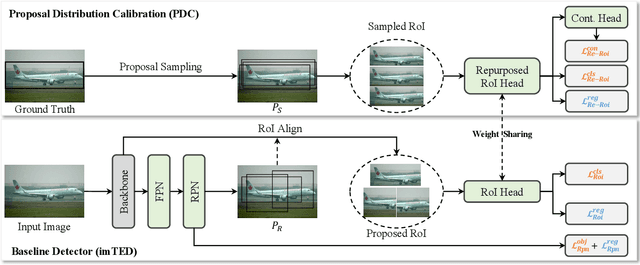
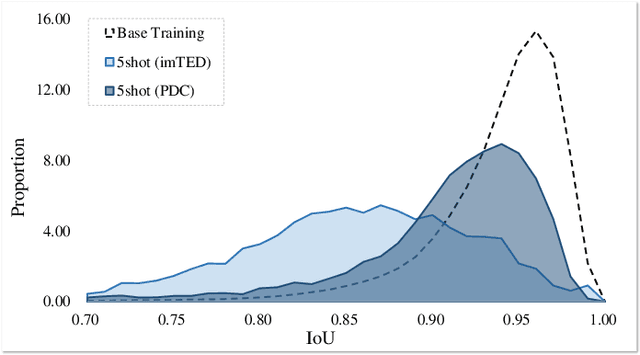
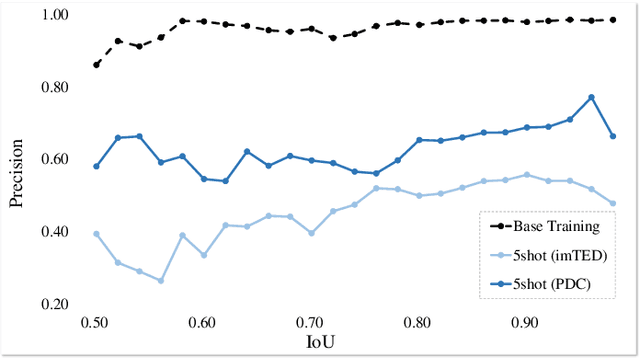
Adapting object detectors learned with sufficient supervision to novel classes under low data regimes is charming yet challenging. In few-shot object detection (FSOD), the two-step training paradigm is widely adopted to mitigate the severe sample imbalance, i.e., holistic pre-training on base classes, then partial fine-tuning in a balanced setting with all classes. Since unlabeled instances are suppressed as backgrounds in the base training phase, the learned RPN is prone to produce biased proposals for novel instances, resulting in dramatic performance degradation. Unfortunately, the extreme data scarcity aggravates the proposal distribution bias, hindering the RoI head from evolving toward novel classes. In this paper, we introduce a simple yet effective proposal distribution calibration (PDC) approach to neatly enhance the localization and classification abilities of the RoI head by recycling its localization ability endowed in base training and enriching high-quality positive samples for semantic fine-tuning. Specifically, we sample proposals based on the base proposal statistics to calibrate the distribution bias and impose additional localization and classification losses upon the sampled proposals for fast expanding the base detector to novel classes. Experiments on the commonly used Pascal VOC and MS COCO datasets with explicit state-of-the-art performances justify the efficacy of our PDC for FSOD. Code is available at github.com/Bohao-Lee/PDC.
Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
Mar 27, 2022



The past year has witnessed a rapid development of masked image modeling (MIM). MIM is mostly built upon the vision transformers, which suggests that self-supervised visual representations can be done by masking input image parts while requiring the target model to recover the missing contents. MIM has demonstrated promising results on downstream tasks, yet we are interested in whether there exist other effective ways to `learn by recovering missing contents'. In this paper, we investigate this topic by designing five other learning objectives that follow the same procedure as MIM but degrade the input image in different ways. With extensive experiments, we manage to summarize a few design principles for token-based pre-training of vision transformers. In particular, the best practice is obtained by keeping the original image style and enriching spatial masking with spatial misalignment -- this design achieves superior performance over MIM in a series of downstream recognition tasks without extra computational cost. The code is available at https://github.com/sunsmarterjie/beyond_masking.
Feature-Gate Coupling for Dynamic Network Pruning
Nov 29, 2021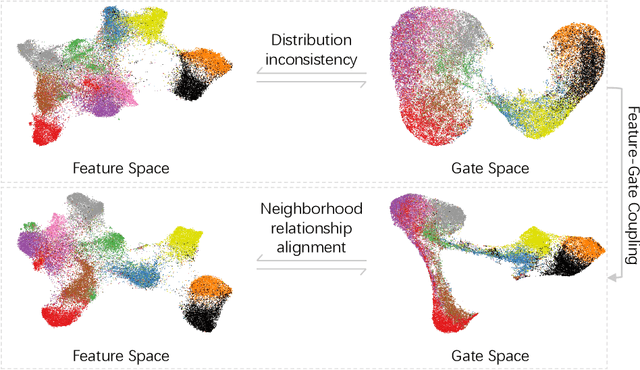
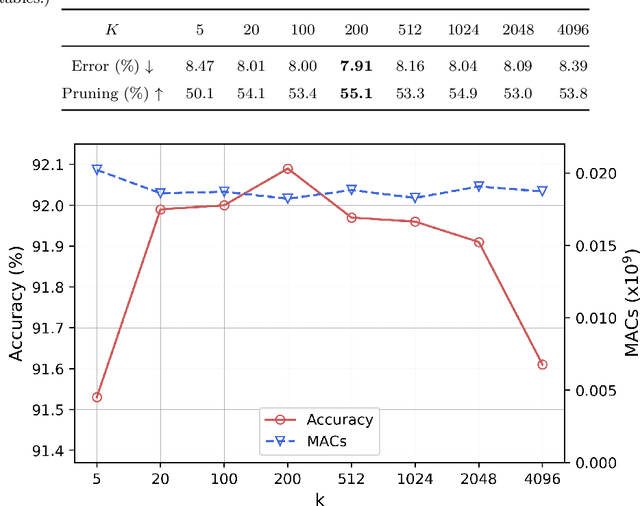
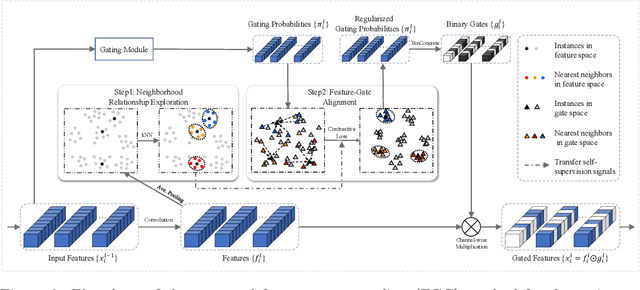
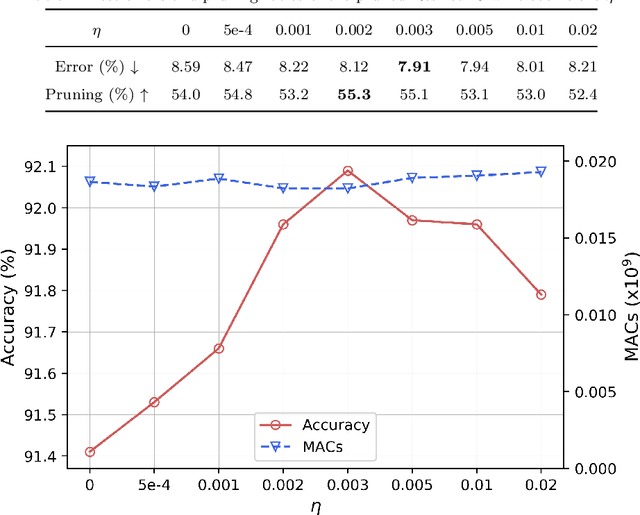
Gating modules have been widely explored in dynamic network pruning to reduce the run-time computational cost of deep neural networks while preserving the representation of features. Despite the substantial progress, existing methods remain ignoring the consistency between feature and gate distributions, which may lead to distortion of gated features. In this paper, we propose a feature-gate coupling (FGC) approach aiming to align distributions of features and gates. FGC is a plug-and-play module, which consists of two steps carried out in an iterative self-supervised manner. In the first step, FGC utilizes the $k$-Nearest Neighbor method in the feature space to explore instance neighborhood relationships, which are treated as self-supervisory signals. In the second step, FGC exploits contrastive learning to regularize gating modules with generated self-supervisory signals, leading to the alignment of instance neighborhood relationships within the feature and gate spaces. Experimental results validate that the proposed FGC method improves the baseline approach with significant margins, outperforming the state-of-the-arts with better accuracy-computation trade-off. Code is publicly available.
A scalable convolutional neural network for task-specified scenarios via knowledge distillation
Jan 06, 2017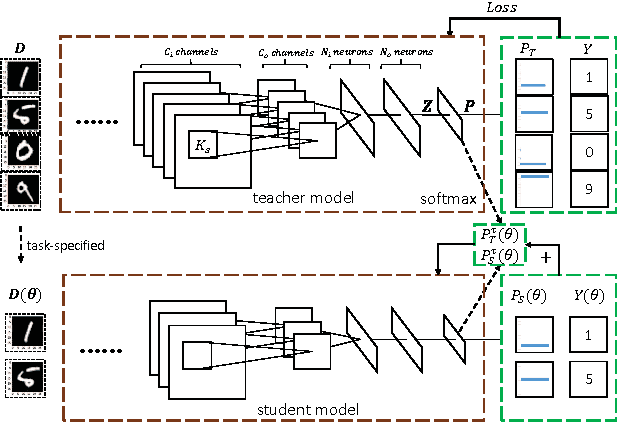
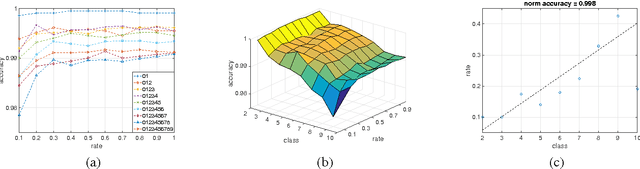
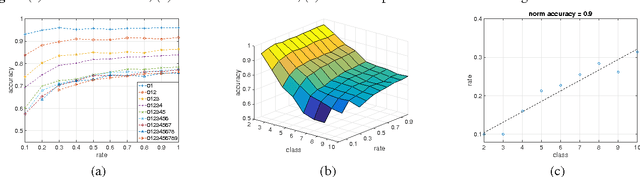
In this paper, we explore the redundancy in convolutional neural network, which scales with the complexity of vision tasks. Considering that many front-end visual systems are interested in only a limited range of visual targets, the removing of task-specified network redundancy can promote a wide range of potential applications. We propose a task-specified knowledge distillation algorithm to derive a simplified model with pre-set computation cost and minimized accuracy loss, which suits the resource constraint front-end systems well. Experiments on the MNIST and CIFAR10 datasets demonstrate the feasibility of the proposed approach as well as the existence of task-specified redundancy.