 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV*: An Efficient Motion Planning Algorithm for Autonomous Vehicles
Aug 08, 2025Autonomous vehicle navigation in structured environments requires planners capable of generating time-optimal, collision-free trajectories that satisfy dynamic and kinematic constraints. We introduce V*, a graph-based motion planner that represents speed and direction as explicit state variables within a discretised space-time-velocity lattice. Unlike traditional methods that decouple spatial search from dynamic feasibility or rely on post-hoc smoothing, V* integrates both motion dimensions directly into graph construction through dynamic graph generation during search expansion. To manage the complexity of high-dimensional search, we employ a hexagonal discretisation strategy and provide formal mathematical proofs establishing optimal waypoint spacing and minimal node redundancy under constrained heading transitions for velocity-aware motion planning. We develop a mathematical formulation for transient steering dynamics in the kinematic bicycle model, modelling steering angle convergence with exponential behaviour, and deriving the relationship for convergence rate parameters. This theoretical foundation, combined with geometric pruning strategies that eliminate expansions leading to infeasible steering configurations, enables V* to evaluate dynamically admissible manoeuvres, ensuring each trajectory is physically realisable without further refinement. We further demonstrate V*'s performance in simulation studies with cluttered and dynamic environments involving moving obstacles, showing its ability to avoid conflicts, yield proactively, and generate safe, efficient trajectories with temporal reasoning capabilities for waiting behaviours and dynamic coordination.
STLLM-DF: A Spatial-Temporal Large Language Model with Diffusion for Enhanced Multi-Mode Traffic System Forecasting
Sep 08, 2024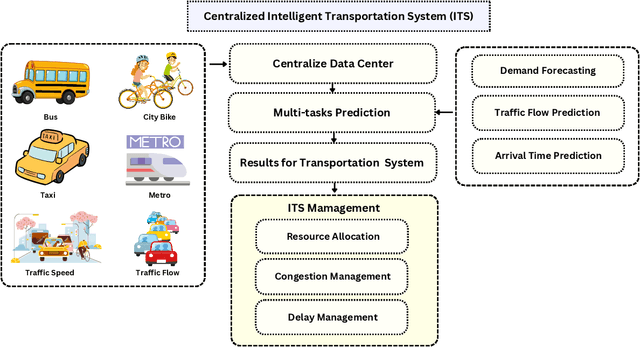
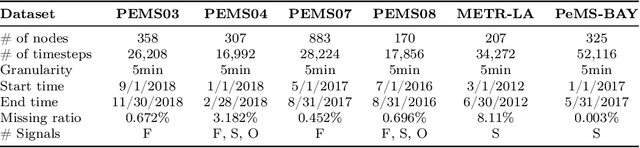
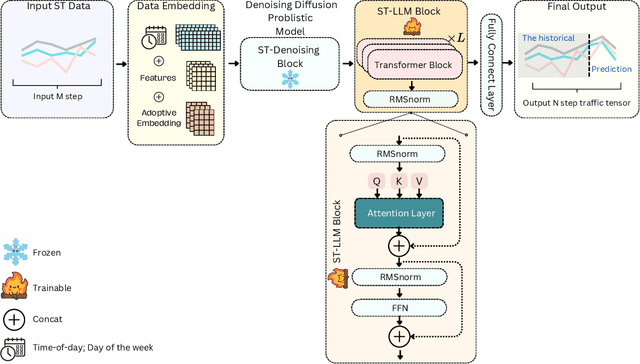

The rapid advancement of Intelligent Transportation Systems (ITS) presents challenges, particularly with missing data in multi-modal transportation and the complexity of handling diverse sequential tasks within a centralized framework. To address these issues, we propose the Spatial-Temporal Large Language Model Diffusion (STLLM-DF), an innovative model that leverages Denoising Diffusion Probabilistic Models (DDPMs) and Large Language Models (LLMs) to improve multi-task transportation prediction. The DDPM's robust denoising capabilities enable it to recover underlying data patterns from noisy inputs, making it particularly effective in complex transportation systems. Meanwhile, the non-pretrained LLM dynamically adapts to spatial-temporal relationships within multi-modal networks, allowing the system to efficiently manage diverse transportation tasks in both long-term and short-term predictions. Extensive experiments demonstrate that STLLM-DF consistently outperforms existing models, achieving an average reduction of 2.40\% in MAE, 4.50\% in RMSE, and 1.51\% in MAPE. This model significantly advances centralized ITS by enhancing predictive accuracy, robustness, and overall system performance across multiple tasks, thus paving the way for more effective spatio-temporal traffic forecasting through the integration of frozen transformer language models and diffusion techniques.
ST-SSMs: Spatial-Temporal Selective State of Space Model for Traffic Forecasting
Apr 20, 2024
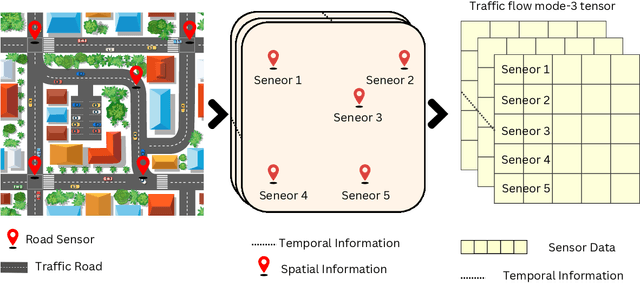

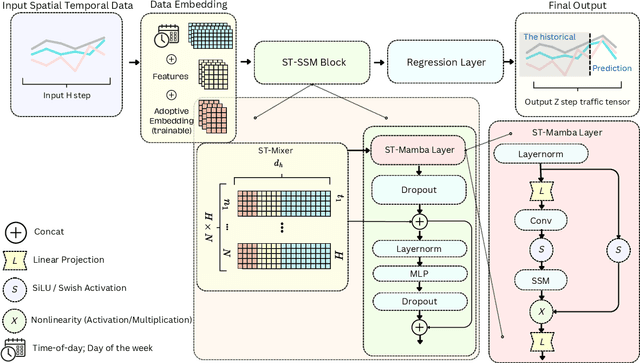
Accurate and efficient traffic prediction is crucial for planning, management, and control of intelligent transportation systems. Most state-of-the-art methods for traffic prediction effectively predict both long-term and short-term by employing spatio-temporal neural networks as prediction models, together with transformers to learn global information on prediction objects (e.g., traffic states of road segments). However, these methods often have a high computational cost to obtain good performance. This paper introduces an innovative approach to traffic flow prediction, the Spatial-Temporal Selective State Space Model (ST-SSMs), featuring the novel ST-Mamba block, which can achieve good prediction accuracy with less computational cost. A comparative analysis highlights the ST-Mamba layer's efficiency, revealing its equivalence to three attention layers, yet with markedly reduced processing time. Through rigorous testing on diverse real-world datasets, the ST-SSMs model demonstrates exceptional improvements in prediction accuracy and computational simplicity, setting new benchmarks in the domain of traffic flow forecasting
CCDSReFormer: Traffic Flow Prediction with a Criss-Crossed Dual-Stream Enhanced Rectified Transformer Model
Mar 29, 2024
Accurate, and effective traffic forecasting is vital for smart traffic systems, crucial in urban traffic planning and management. Current Spatio-Temporal Transformer models, despite their prediction capabilities, struggle with balancing computational efficiency and accuracy, favoring global over local information, and handling spatial and temporal data separately, limiting insight into complex interactions. We introduce the Criss-Crossed Dual-Stream Enhanced Rectified Transformer model (CCDSReFormer), which includes three innovative modules: Enhanced Rectified Spatial Self-attention (ReSSA), Enhanced Rectified Delay Aware Self-attention (ReDASA), and Enhanced Rectified Temporal Self-attention (ReTSA). These modules aim to lower computational needs via sparse attention, focus on local information for better traffic dynamics understanding, and merge spatial and temporal insights through a unique learning method. Extensive tests on six real-world datasets highlight CCDSReFormer's superior performance. An ablation study also confirms the significant impact of each component on the model's predictive accuracy, showcasing our model's ability to forecast traffic flow effectively.