 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCDSReFormer: Traffic Flow Prediction with a Criss-Crossed Dual-Stream Enhanced Rectified Transformer Model
Paper and Code
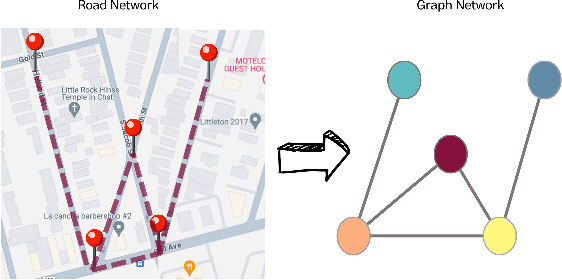
Accurate, and effective traffic forecasting is vital for smart traffic systems, crucial in urban traffic planning and management. Current Spatio-Temporal Transformer models, despite their prediction capabilities, struggle with balancing computational efficiency and accuracy, favoring global over local information, and handling spatial and temporal data separately, limiting insight into complex interactions. We introduce the Criss-Crossed Dual-Stream Enhanced Rectified Transformer model (CCDSReFormer), which includes three innovative modules: Enhanced Rectified Spatial Self-attention (ReSSA), Enhanced Rectified Delay Aware Self-attention (ReDASA), and Enhanced Rectified Temporal Self-attention (ReTSA). These modules aim to lower computational needs via sparse attention, focus on local information for better traffic dynamics understanding, and merge spatial and temporal insights through a unique learning method. Extensive tests on six real-world datasets highlight CCDSReFormer's superior performance. An ablation study also confirms the significant impact of each component on the model's predictive accuracy, showcasing our model's ability to forecast traffic flow effectively.