 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-MambaSync: The Complement of Mamba and Transformers for Spatial-Temporal in Traffic Flow Prediction
May 09, 2024



Accurate traffic flow prediction is crucial for optimizing traffic management, enhancing road safety, and reducing environmental impacts. Existing models face challenges with long sequence data, requiring substantial memory and computational resources, and often suffer from slow inference times due to the lack of a unified summary state. This paper introduces ST-MambaSync, an innovative traffic flow prediction model that combines transformer technology with the ST-Mamba block, representing a significant advancement in the field. We are the pioneers in employing the Mamba mechanism which is an attention mechanism integrated with ResNet within a transformer framework, which significantly enhances the model's explainability and performance. ST-MambaSync effectively addresses key challenges such as data length and computational efficiency, setting new benchmarks for accuracy and processing speed through comprehensive comparative analysis. This development has significant implications for urban planning and real-time traffic management, establishing a new standard in traffic flow prediction technology.
ST-MambaSync: The Confluence of Mamba Structure and Spatio-Temporal Transformers for Precipitous Traffic Prediction
Apr 26, 2024Balancing accuracy with computational efficiency is paramount in machine learning, particularly when dealing with high-dimensional data, such as spatial-temporal datasets. This study introduces ST-MambaSync, an innovative framework that integrates a streamlined attention layer with a simplified state-space layer. The model achieves competitive accuracy in spatial-temporal prediction tasks. We delve into the relationship between attention mechanisms and the Mamba component, revealing that Mamba functions akin to attention within a residual network structure. This comparative analysis underpins the efficiency of state-space models, elucidating their capability to deliver superior performance at reduced computational costs.
CCDSReFormer: Traffic Flow Prediction with a Criss-Crossed Dual-Stream Enhanced Rectified Transformer Model
Mar 29, 2024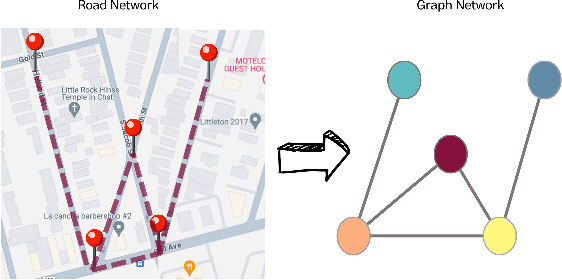
Accurate, and effective traffic forecasting is vital for smart traffic systems, crucial in urban traffic planning and management. Current Spatio-Temporal Transformer models, despite their prediction capabilities, struggle with balancing computational efficiency and accuracy, favoring global over local information, and handling spatial and temporal data separately, limiting insight into complex interactions. We introduce the Criss-Crossed Dual-Stream Enhanced Rectified Transformer model (CCDSReFormer), which includes three innovative modules: Enhanced Rectified Spatial Self-attention (ReSSA), Enhanced Rectified Delay Aware Self-attention (ReDASA), and Enhanced Rectified Temporal Self-attention (ReTSA). These modules aim to lower computational needs via sparse attention, focus on local information for better traffic dynamics understanding, and merge spatial and temporal insights through a unique learning method. Extensive tests on six real-world datasets highlight CCDSReFormer's superior performance. An ablation study also confirms the significant impact of each component on the model's predictive accuracy, showcasing our model's ability to forecast traffic flow effectively.