 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTLLM-DF: A Spatial-Temporal Large Language Model with Diffusion for Enhanced Multi-Mode Traffic System Forecasting
Sep 08, 2024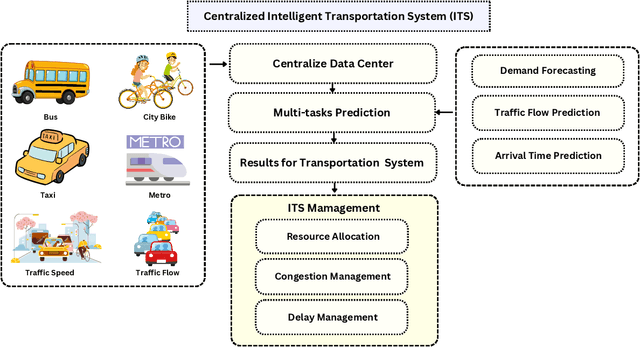
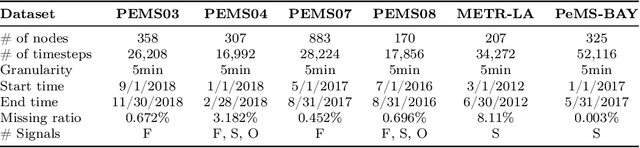
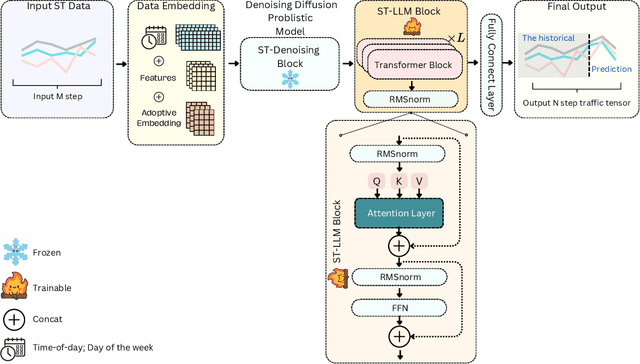

The rapid advancement of Intelligent Transportation Systems (ITS) presents challenges, particularly with missing data in multi-modal transportation and the complexity of handling diverse sequential tasks within a centralized framework. To address these issues, we propose the Spatial-Temporal Large Language Model Diffusion (STLLM-DF), an innovative model that leverages Denoising Diffusion Probabilistic Models (DDPMs) and Large Language Models (LLMs) to improve multi-task transportation prediction. The DDPM's robust denoising capabilities enable it to recover underlying data patterns from noisy inputs, making it particularly effective in complex transportation systems. Meanwhile, the non-pretrained LLM dynamically adapts to spatial-temporal relationships within multi-modal networks, allowing the system to efficiently manage diverse transportation tasks in both long-term and short-term predictions. Extensive experiments demonstrate that STLLM-DF consistently outperforms existing models, achieving an average reduction of 2.40\% in MAE, 4.50\% in RMSE, and 1.51\% in MAPE. This model significantly advances centralized ITS by enhancing predictive accuracy, robustness, and overall system performance across multiple tasks, thus paving the way for more effective spatio-temporal traffic forecasting through the integration of frozen transformer language models and diffusion techniques.
ST-MambaSync: The Complement of Mamba and Transformers for Spatial-Temporal in Traffic Flow Prediction
May 09, 2024



Accurate traffic flow prediction is crucial for optimizing traffic management, enhancing road safety, and reducing environmental impacts. Existing models face challenges with long sequence data, requiring substantial memory and computational resources, and often suffer from slow inference times due to the lack of a unified summary state. This paper introduces ST-MambaSync, an innovative traffic flow prediction model that combines transformer technology with the ST-Mamba block, representing a significant advancement in the field. We are the pioneers in employing the Mamba mechanism which is an attention mechanism integrated with ResNet within a transformer framework, which significantly enhances the model's explainability and performance. ST-MambaSync effectively addresses key challenges such as data length and computational efficiency, setting new benchmarks for accuracy and processing speed through comprehensive comparative analysis. This development has significant implications for urban planning and real-time traffic management, establishing a new standard in traffic flow prediction technology.
ST-MambaSync: The Confluence of Mamba Structure and Spatio-Temporal Transformers for Precipitous Traffic Prediction
Apr 26, 2024Balancing accuracy with computational efficiency is paramount in machine learning, particularly when dealing with high-dimensional data, such as spatial-temporal datasets. This study introduces ST-MambaSync, an innovative framework that integrates a streamlined attention layer with a simplified state-space layer. The model achieves competitive accuracy in spatial-temporal prediction tasks. We delve into the relationship between attention mechanisms and the Mamba component, revealing that Mamba functions akin to attention within a residual network structure. This comparative analysis underpins the efficiency of state-space models, elucidating their capability to deliver superior performance at reduced computational costs.
ST-SSMs: Spatial-Temporal Selective State of Space Model for Traffic Forecasting
Apr 20, 2024
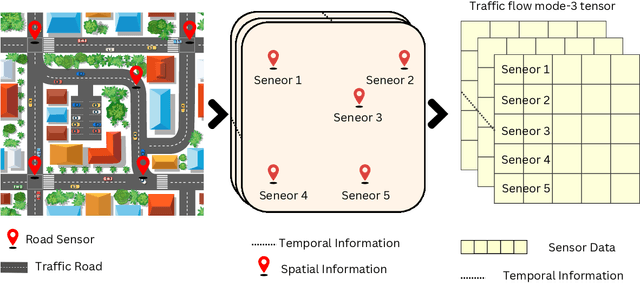

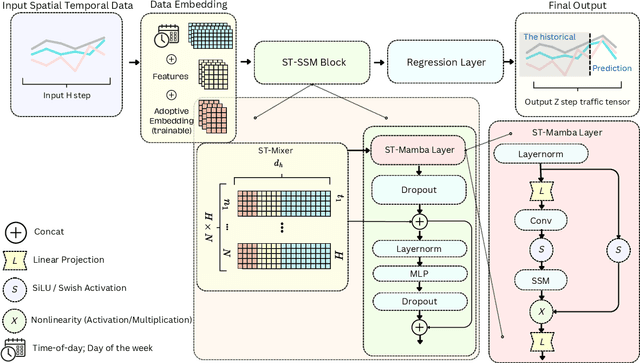
Accurate and efficient traffic prediction is crucial for planning, management, and control of intelligent transportation systems. Most state-of-the-art methods for traffic prediction effectively predict both long-term and short-term by employing spatio-temporal neural networks as prediction models, together with transformers to learn global information on prediction objects (e.g., traffic states of road segments). However, these methods often have a high computational cost to obtain good performance. This paper introduces an innovative approach to traffic flow prediction, the Spatial-Temporal Selective State Space Model (ST-SSMs), featuring the novel ST-Mamba block, which can achieve good prediction accuracy with less computational cost. A comparative analysis highlights the ST-Mamba layer's efficiency, revealing its equivalence to three attention layers, yet with markedly reduced processing time. Through rigorous testing on diverse real-world datasets, the ST-SSMs model demonstrates exceptional improvements in prediction accuracy and computational simplicity, setting new benchmarks in the domain of traffic flow forecasting
CCDSReFormer: Traffic Flow Prediction with a Criss-Crossed Dual-Stream Enhanced Rectified Transformer Model
Mar 29, 2024
Accurate, and effective traffic forecasting is vital for smart traffic systems, crucial in urban traffic planning and management. Current Spatio-Temporal Transformer models, despite their prediction capabilities, struggle with balancing computational efficiency and accuracy, favoring global over local information, and handling spatial and temporal data separately, limiting insight into complex interactions. We introduce the Criss-Crossed Dual-Stream Enhanced Rectified Transformer model (CCDSReFormer), which includes three innovative modules: Enhanced Rectified Spatial Self-attention (ReSSA), Enhanced Rectified Delay Aware Self-attention (ReDASA), and Enhanced Rectified Temporal Self-attention (ReTSA). These modules aim to lower computational needs via sparse attention, focus on local information for better traffic dynamics understanding, and merge spatial and temporal insights through a unique learning method. Extensive tests on six real-world datasets highlight CCDSReFormer's superior performance. An ablation study also confirms the significant impact of each component on the model's predictive accuracy, showcasing our model's ability to forecast traffic flow effectively.
Unifying over-smoothing and over-squashing in graph neural networks: A physics informed approach and beyond
Sep 13, 2023Graph Neural Networks (GNNs) have emerged as one of the leading approaches for machine learning on graph-structured data. Despite their great success, critical computational challenges such as over-smoothing, over-squashing, and limited expressive power continue to impact the performance of GNNs. In this study, inspired from the time-reversal principle commonly utilized in classical and quantum physics, we reverse the time direction of the graph heat equation. The resulted reversing process yields a class of high pass filtering functions that enhance the sharpness of graph node features. Leveraging this concept, we introduce the Multi-Scaled Heat Kernel based GNN (MHKG) by amalgamating diverse filtering functions' effects on node features. To explore more flexible filtering conditions, we further generalize MHKG into a model termed G-MHKG and thoroughly show the roles of each element in controlling over-smoothing, over-squashing and expressive power. Notably, we illustrate that all aforementioned issues can be characterized and analyzed via the properties of the filtering functions, and uncover a trade-off between over-smoothing and over-squashing: enhancing node feature sharpness will make model suffer more from over-squashing, and vice versa. Furthermore, we manipulate the time again to show how G-MHKG can handle both two issues under mild conditions. Our conclusive experiments highlight the effectiveness of proposed models. It surpasses several GNN baseline models in performance across graph datasets characterized by both homophily and heterophily.
How Curvature Enhance the Adaptation Power of Framelet GCNs
Jul 19, 2023



Graph neural network (GNN) has been demonstrated powerful in modeling graph-structured data. However, despite many successful cases of applying GNNs to various graph classification and prediction tasks, whether the graph geometrical information has been fully exploited to enhance the learning performance of GNNs is not yet well understood. This paper introduces a new approach to enhance GNN by discrete graph Ricci curvature. Specifically, the graph Ricci curvature defined on the edges of a graph measures how difficult the information transits on one edge from one node to another based on their neighborhoods. Motivated by the geometric analogy of Ricci curvature in the graph setting, we prove that by inserting the curvature information with different carefully designed transformation function $\zeta$, several known computational issues in GNN such as over-smoothing can be alleviated in our proposed model. Furthermore, we verified that edges with very positive Ricci curvature (i.e., $\kappa_{i,j} \approx 1$) are preferred to be dropped to enhance model's adaption to heterophily graph and one curvature based graph edge drop algorithm is proposed. Comprehensive experiments show that our curvature-based GNN model outperforms the state-of-the-art baselines in both homophily and heterophily graph datasets, indicating the effectiveness of involving graph geometric information in GNNs.
Frameless Graph Knowledge Distillation
Jul 13, 2023Knowledge distillation (KD) has shown great potential for transferring knowledge from a complex teacher model to a simple student model in which the heavy learning task can be accomplished efficiently and without losing too much prediction accuracy. Recently, many attempts have been made by applying the KD mechanism to the graph representation learning models such as graph neural networks (GNNs) to accelerate the model's inference speed via student models. However, many existing KD-based GNNs utilize MLP as a universal approximator in the student model to imitate the teacher model's process without considering the graph knowledge from the teacher model. In this work, we provide a KD-based framework on multi-scaled GNNs, known as graph framelet, and prove that by adequately utilizing the graph knowledge in a multi-scaled manner provided by graph framelet decomposition, the student model is capable of adapting both homophilic and heterophilic graphs and has the potential of alleviating the over-squashing issue with a simple yet effectively graph surgery. Furthermore, we show how the graph knowledge supplied by the teacher is learned and digested by the student model via both algebra and geometry. Comprehensive experiments show that our proposed model can generate learning accuracy identical to or even surpass the teacher model while maintaining the high speed of inference.
Revisiting Generalized p-Laplacian Regularized Framelet GCNs: Convergence, Energy Dynamic and Training with Non-Linear Diffusion
May 25, 2023This work presents a comprehensive theoretical analysis of graph p-Laplacian based framelet network (pL-UFG) to establish a solid understanding of its properties. We begin by conducting a convergence analysis of the p-Laplacian based implicit layer integrated after the framelet convolution, providing insights into the asymptotic behavior of pL-UFG. By exploring the generalized Dirichlet energy of pL-UFG, we demonstrate that the Dirichlet energy remains non-zero, ensuring the avoidance of over-smoothing issues in pL-UFG as it approaches convergence. Furthermore, we elucidate the dynamic energy perspective through which the implicit layer in pL-UFG synergizes with graph framelets, enhancing the model's adaptability to both homophilic and heterophilic data. Remarkably, we establish that the implicit layer can be interpreted as a generalized non-linear diffusion process, enabling training using diverse schemes. These multifaceted analyses lead to unified conclusions that provide novel insights for understanding and implementing pL-UFG, contributing to advancements in the field of graph-based deep learning.
Generalized Laplacian Regularized Framelet GCNs
Oct 27, 2022This paper introduces a novel Framelet Graph approach based on p-Laplacian GNN. The proposed two models, named p-Laplacian undecimated framelet graph convolution (pL-UFG) and generalized p-Laplacian undecimated framelet graph convolution (pL-fUFG) inherit the nature of p-Laplacian with the expressive power of multi-resolution decomposition of graph signals. The empirical study highlights the excellent performance of the pL-UFG and pL-fUFG in different graph learning tasks including node classification and signal denoising.