 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Prompt Fits All: Universal Graph Adaptation for Pretrained Models
Sep 26, 2025Graph Prompt Learning (GPL) has emerged as a promising paradigm that bridges graph pretraining models and downstream scenarios, mitigating label dependency and the misalignment between upstream pretraining and downstream tasks. Although existing GPL studies explore various prompt strategies, their effectiveness and underlying principles remain unclear. We identify two critical limitations: (1) Lack of consensus on underlying mechanisms: Despite current GPLs have advanced the field, there is no consensus on how prompts interact with pretrained models, as different strategies intervene at varying spaces within the model, i.e., input-level, layer-wise, and representation-level prompts. (2) Limited scenario adaptability: Most methods fail to generalize across diverse downstream scenarios, especially under data distribution shifts (e.g., homophilic-to-heterophilic graphs). To address these issues, we theoretically analyze existing GPL approaches and reveal that representation-level prompts essentially function as fine-tuning a simple downstream classifier, proposing that graph prompt learning should focus on unleashing the capability of pretrained models, and the classifier adapts to downstream scenarios. Based on our findings, we propose UniPrompt, a novel GPL method that adapts any pretrained models, unleashing the capability of pretrained models while preserving the structure of the input graph. Extensive experiments demonstrate that our method can effectively integrate with various pretrained models and achieve strong performance across in-domain and cross-domain scenarios.
Advancing Automated Knowledge Transfer in Evolutionary Multitasking via Large Language Models
Sep 06, 2024



Evolutionary Multi-task Optimization (EMTO) is a paradigm that leverages knowledge transfer across simultaneously optimized tasks for enhanced search performance. To facilitate EMTO's performance, various knowledge transfer models have been developed for specific optimization tasks. However, designing these models often requires substantial expert knowledge. Recently, large language models (LLMs) have achieved remarkable success in autonomous programming, aiming to produce effective solvers for specific problems. In this work, a LLM-based optimization paradigm is introduced to establish an autonomous model factory for generating knowledge transfer models, ensuring effective and efficient knowledge transfer across various optimization tasks. To evaluate the performance of the proposed method, we conducted comprehensive empirical studies comparing the knowledge transfer model generated by the LLM with existing state-of-the-art knowledge transfer methods. The results demonstrate that the generated model is able to achieve superior or competitive performance against hand-crafted knowledge transfer models in terms of both efficiency and effectiveness.
Learning to Transfer for Evolutionary Multitasking
Jun 20, 2024



Evolutionary multitasking (EMT) is an emerging approach for solving multitask optimization problems (MTOPs) and has garnered considerable research interest. The implicit EMT is a significant research branch that utilizes evolution operators to enable knowledge transfer (KT) between tasks. However, current approaches in implicit EMT face challenges in adaptability, due to the use of a limited number of evolution operators and insufficient utilization of evolutionary states for performing KT. This results in suboptimal exploitation of implicit KT's potential to tackle a variety of MTOPs. To overcome these limitations, we propose a novel Learning to Transfer (L2T) framework to automatically discover efficient KT policies for the MTOPs at hand. Our framework conceptualizes the KT process as a learning agent's sequence of strategic decisions within the EMT process. We propose an action formulation for deciding when and how to transfer, a state representation with informative features of evolution states, a reward formulation concerning convergence and transfer efficiency gain, and the environment for the agent to interact with MTOPs. We employ an actor-critic network structure for the agent and learn it via proximal policy optimization. This learned agent can be integrated with various evolutionary algorithms, enhancing their ability to address a range of new MTOPs. Comprehensive empirical studies on both synthetic and real-world MTOPs, encompassing diverse inter-task relationships, function classes, and task distributions are conducted to validate the proposed L2T framework. The results show a marked improvement in the adaptability and performance of implicit EMT when solving a wide spectrum of unseen MTOPs.
Towards Next Era of Multi-objective Optimization: Large Language Models as Architects of Evolutionary Operators
Jun 13, 2024



Multi-objective optimization problems (MOPs) are prevalent in various real-world applications, necessitating sophisticated solutions that balance conflicting objectives. Traditional evolutionary algorithms (EAs), while effective, often rely on domain-specific expert knowledge and iterative tuning, which can impede innovation when encountering novel MOPs. Very recently, the emergence of Large Language Models (LLMs) has revolutionized software engineering by enabling the autonomous development and refinement of programs. Capitalizing on this advancement, we propose a new LLM-based framework for evolving EA operators, designed to address a wide array of MOPs. This framework facilitates the production of EA operators without the extensive demands for expert intervention, thereby streamlining the design process. To validate the efficacy of our approach, we have conducted extensive empirical studies across various categories of MOPs. The results demonstrate the robustness and superior performance of our LLM-evolved operators.
Unlock the Power of Algorithm Features: A Generalization Analysis for Algorithm Selection
May 18, 2024



In the field of algorithm selection research, the discussion surrounding algorithm features has been significantly overshadowed by the emphasis on problem features. Although a few empirical studies have yielded evidence regarding the effectiveness of algorithm features, the potential benefits of incorporating algorithm features into algorithm selection models and their suitability for different scenarios remain unclear. It is evident that relying solely on empirical research cannot adequately elucidate the mechanisms underlying performance variations. In this paper, we address this gap by proposing the first provable guarantee for algorithm selection based on algorithm features, taking a generalization perspective. We analyze the benefits and costs associated with algorithm features and investigate how the generalization error is affected by several factors. Specifically, we examine adaptive and predefined algorithm features under transductive and inductive learning paradigms, respectively, and derive upper bounds for the generalization error based on their model's Rademacher complexity. Our theoretical findings not only provide tight upper bounds, but also offer analytical insights into the impact of various factors, including model complexity, the number of problem instances and candidate algorithms, model parameters and feature values, and distributional differences between the training and test sets. Notably, we demonstrate that algorithm feature-based models outperform traditional models relying solely on problem features in complex multi-algorithm scenarios in terms of generalization, and are particularly well-suited for deployment in scenarios under distribution shifts, where the generalization error exhibits a positive correlation with the chi-square distance between training and test sets.
How Multimodal Integration Boost the Performance of LLM for Optimization: Case Study on Capacitated Vehicle Routing Problems
Mar 04, 2024



Recently, large language models (LLMs) have notably positioned them as capable tools for addressing complex optimization challenges. Despite this recognition, a predominant limitation of existing LLM-based optimization methods is their struggle to capture the relationships among decision variables when relying exclusively on numerical text prompts, especially in high-dimensional problems. Keeping this in mind, we first propose to enhance the optimization performance using multimodal LLM capable of processing both textual and visual prompts for deeper insights of the processed optimization problem. This integration allows for a more comprehensive understanding of optimization problems, akin to human cognitive processes. We have developed a multimodal LLM-based optimization framework that simulates human problem-solving workflows, thereby offering a more nuanced and effective analysis. The efficacy of this method is evaluated through extensive empirical studies focused on a well-known combinatorial optimization problem, i.e., capacitated vehicle routing problem. The results are compared against those obtained from the LLM-based optimization algorithms that rely solely on textual prompts, demonstrating the significant advantages of our multimodal approach.
Asynchronous and Segmented Bidirectional Encoding for NMT
Feb 19, 2024


With the rapid advancement of Neural Machine Translation (NMT), enhancing translation efficiency and quality has become a focal point of research. Despite the commendable performance of general models such as the Transformer in various aspects, they still fall short in processing long sentences and fully leveraging bidirectional contextual information. This paper introduces an improved model based on the Transformer, implementing an asynchronous and segmented bidirectional decoding strategy aimed at elevating translation efficiency and accuracy. Compared to traditional unidirectional translations from left-to-right or right-to-left, our method demonstrates heightened efficiency and improved translation quality, particularly in handling long sentences. Experimental results on the IWSLT2017 dataset confirm the effectiveness of our approach in accelerating translation and increasing accuracy, especially surpassing traditional unidirectional strategies in long sentence translation. Furthermore, this study analyzes the impact of sentence length on decoding outcomes and explores the model's performance in various scenarios. The findings of this research not only provide an effective encoding strategy for the NMT field but also pave new avenues and directions for future studies.
Efficient Reinforcemen Learning via Decoupling Exploration and Utilization
Jan 17, 2024Deep neural network(DNN) generalization is limited by the over-reliance of current offline reinforcement learning techniques on conservative processing of existing datasets. This method frequently results in algorithms that settle for suboptimal solutions that only adjust to a certain dataset. Similarly, in online reinforcement learning, the previously imposed punitive pessimism also deprives the model of its exploratory potential. Our research proposes a novel framework, Optimistic and Pessimistic Actor Reinforcement Learning (OPARL). OPARL employs a unique dual-actor approach: an optimistic actor dedicated to exploration and a pessimistic actor focused on utilization, thereby effectively differentiating between exploration and utilization strategies. This unique combination in reinforcement learning methods fosters a more balanced and efficient approach. It enables the optimization of policies that focus on actions yielding high rewards through pessimistic utilization strategies, while also ensuring extensive state coverage via optimistic exploration. Experiments and theoretical study demonstrates OPARL improves agents' capacities for application and exploration. In the most tasks of DMControl benchmark and Mujoco environment, OPARL performed better than state-of-the-art methods. Our code has released on https://github.com/yydsok/OPARL
CIGAN: A Python Package for Handling Class Imbalance using Generative Adversarial Networks
Aug 04, 2022


A key challenge in Machine Learning is class imbalance, where the sample size of some classes (majority classes) are much higher than that of the other classes (minority classes). If we were to train a classifier directly on imbalanced data, it is more likely for the classifier to predict a new sample as one of the majority classes. In the extreme case, the classifier could completely ignore the minority classes. This could have serious sociological implications in healthcare, as the minority classes are usually the disease classes (e.g., death or positive clinical test result). In this paper, we introduce a software that uses Generative Adversarial Networks to oversample the minority classes so as to improve downstream classification. To the best of our knowledge, this is the first tool that allows multi-class classification (where the target can have an arbitrary number of classes). The code of the tool is publicly available in our github repository (https://github.com/yuxiaohuang/research/tree/master/gwu/working/cigan/code).
Powerful Graph Convolutioal Networks with Adaptive Propagation Mechanism for Homophily and Heterophily
Dec 27, 2021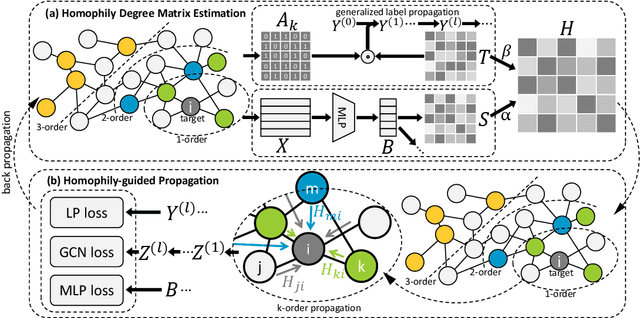
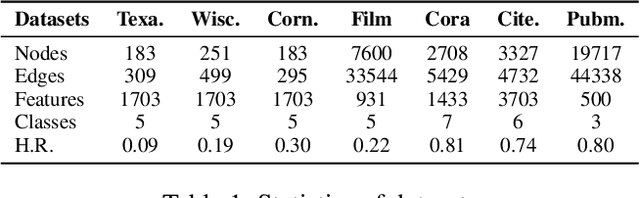
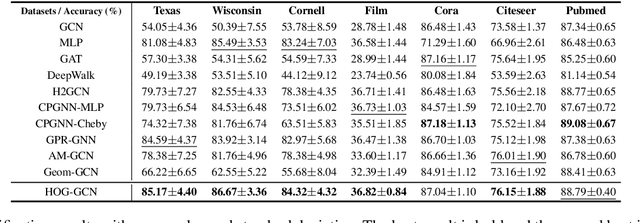

Graph Convolutional Networks (GCNs) have been widely applied in various fields due to their significant power on processing graph-structured data. Typical GCN and its variants work under a homophily assumption (i.e., nodes with same class are prone to connect to each other), while ignoring the heterophily which exists in many real-world networks (i.e., nodes with different classes tend to form edges). Existing methods deal with heterophily by mainly aggregating higher-order neighborhoods or combing the immediate representations, which leads to noise and irrelevant information in the result. But these methods did not change the propagation mechanism which works under homophily assumption (that is a fundamental part of GCNs). This makes it difficult to distinguish the representation of nodes from different classes. To address this problem, in this paper we design a novel propagation mechanism, which can automatically change the propagation and aggregation process according to homophily or heterophily between node pairs. To adaptively learn the propagation process, we introduce two measurements of homophily degree between node pairs, which is learned based on topological and attribute information, respectively. Then we incorporate the learnable homophily degree into the graph convolution framework, which is trained in an end-to-end schema, enabling it to go beyond the assumption of homophily. More importantly, we theoretically prove that our model can constrain the similarity of representations between nodes according to their homophily degree. Experiments on seven real-world datasets demonstrate that this new approach outperforms the state-of-the-art methods under heterophily or low homophily, and gains competitive performance under homophily.