 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Automated Knowledge Transfer in Evolutionary Multitasking via Large Language Models
Sep 06, 2024



Evolutionary Multi-task Optimization (EMTO) is a paradigm that leverages knowledge transfer across simultaneously optimized tasks for enhanced search performance. To facilitate EMTO's performance, various knowledge transfer models have been developed for specific optimization tasks. However, designing these models often requires substantial expert knowledge. Recently, large language models (LLMs) have achieved remarkable success in autonomous programming, aiming to produce effective solvers for specific problems. In this work, a LLM-based optimization paradigm is introduced to establish an autonomous model factory for generating knowledge transfer models, ensuring effective and efficient knowledge transfer across various optimization tasks. To evaluate the performance of the proposed method, we conducted comprehensive empirical studies comparing the knowledge transfer model generated by the LLM with existing state-of-the-art knowledge transfer methods. The results demonstrate that the generated model is able to achieve superior or competitive performance against hand-crafted knowledge transfer models in terms of both efficiency and effectiveness.
Towards Next Era of Multi-objective Optimization: Large Language Models as Architects of Evolutionary Operators
Jun 13, 2024



Multi-objective optimization problems (MOPs) are prevalent in various real-world applications, necessitating sophisticated solutions that balance conflicting objectives. Traditional evolutionary algorithms (EAs), while effective, often rely on domain-specific expert knowledge and iterative tuning, which can impede innovation when encountering novel MOPs. Very recently, the emergence of Large Language Models (LLMs) has revolutionized software engineering by enabling the autonomous development and refinement of programs. Capitalizing on this advancement, we propose a new LLM-based framework for evolving EA operators, designed to address a wide array of MOPs. This framework facilitates the production of EA operators without the extensive demands for expert intervention, thereby streamlining the design process. To validate the efficacy of our approach, we have conducted extensive empirical studies across various categories of MOPs. The results demonstrate the robustness and superior performance of our LLM-evolved operators.
Deconstructing The Ethics of Large Language Models from Long-standing Issues to New-emerging Dilemmas
Jun 08, 2024


Large Language Models (LLMs) have achieved unparalleled success across diverse language modeling tasks in recent years. However, this progress has also intensified ethical concerns, impacting the deployment of LLMs in everyday contexts. This paper provides a comprehensive survey of ethical challenges associated with LLMs, from longstanding issues such as copyright infringement, systematic bias, and data privacy, to emerging problems like truthfulness and social norms. We critically analyze existing research aimed at understanding, examining, and mitigating these ethical risks. Our survey underscores integrating ethical standards and societal values into the development of LLMs, thereby guiding the development of responsible and ethically aligned language models.
Unlock the Power of Algorithm Features: A Generalization Analysis for Algorithm Selection
May 18, 2024



In the field of algorithm selection research, the discussion surrounding algorithm features has been significantly overshadowed by the emphasis on problem features. Although a few empirical studies have yielded evidence regarding the effectiveness of algorithm features, the potential benefits of incorporating algorithm features into algorithm selection models and their suitability for different scenarios remain unclear. It is evident that relying solely on empirical research cannot adequately elucidate the mechanisms underlying performance variations. In this paper, we address this gap by proposing the first provable guarantee for algorithm selection based on algorithm features, taking a generalization perspective. We analyze the benefits and costs associated with algorithm features and investigate how the generalization error is affected by several factors. Specifically, we examine adaptive and predefined algorithm features under transductive and inductive learning paradigms, respectively, and derive upper bounds for the generalization error based on their model's Rademacher complexity. Our theoretical findings not only provide tight upper bounds, but also offer analytical insights into the impact of various factors, including model complexity, the number of problem instances and candidate algorithms, model parameters and feature values, and distributional differences between the training and test sets. Notably, we demonstrate that algorithm feature-based models outperform traditional models relying solely on problem features in complex multi-algorithm scenarios in terms of generalization, and are particularly well-suited for deployment in scenarios under distribution shifts, where the generalization error exhibits a positive correlation with the chi-square distance between training and test sets.
Counterfactual Generative Models for Time-Varying Treatments
May 25, 2023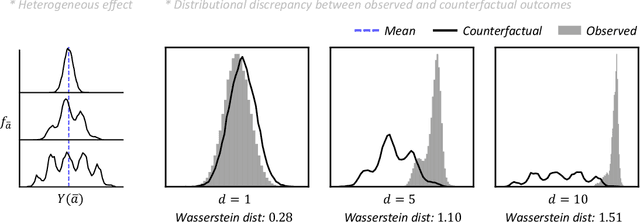

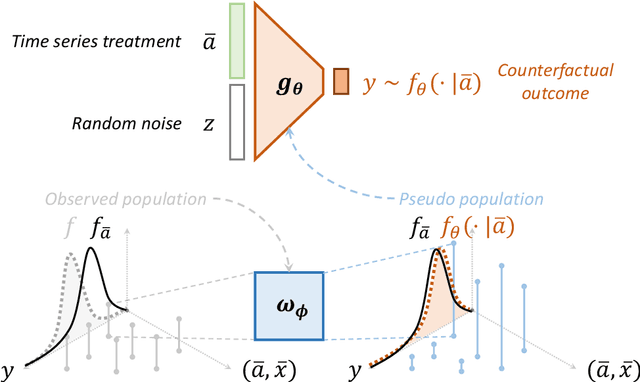
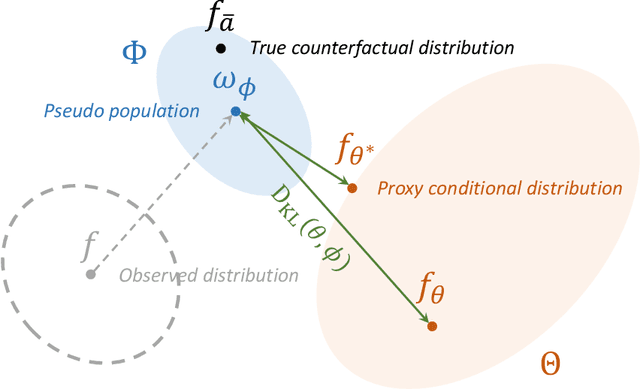
Estimating average causal effects is a common practice to test new treatments. However, the average effect ''masks'' important individual characteristics in the counterfactual distribution, which may lead to safety, fairness, and ethical concerns. This issue is exacerbated in the temporal setting, where the treatment is sequential and time-varying, leading to an intricate influence on the counterfactual distribution. In this paper, we propose a novel conditional generative modeling approach to capture the whole counterfactual distribution, allowing efficient inference on certain statistics of the counterfactual distribution. This makes the proposed approach particularly suitable for healthcare and public policy making. Our generative modeling approach carefully tackles the distribution mismatch in the observed data and the targeted counterfactual distribution via a marginal structural model. Our method outperforms state-of-the-art baselines on both synthetic and real data.