 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSKV: Training-Efficient Channel Shrinking for KV Cache in Long-Context Scenarios
Paper and Code
Sep 16, 2024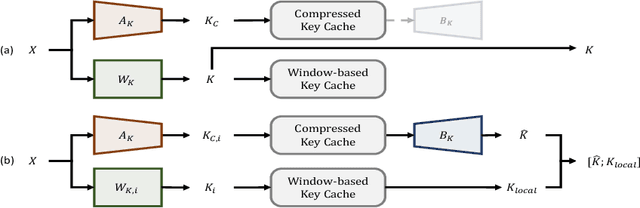
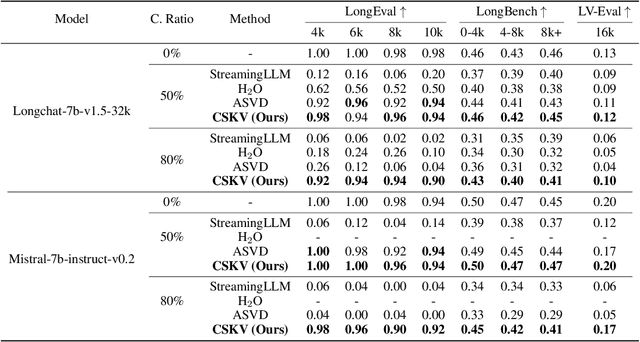
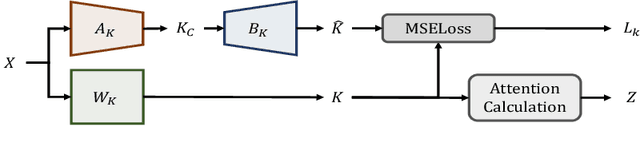
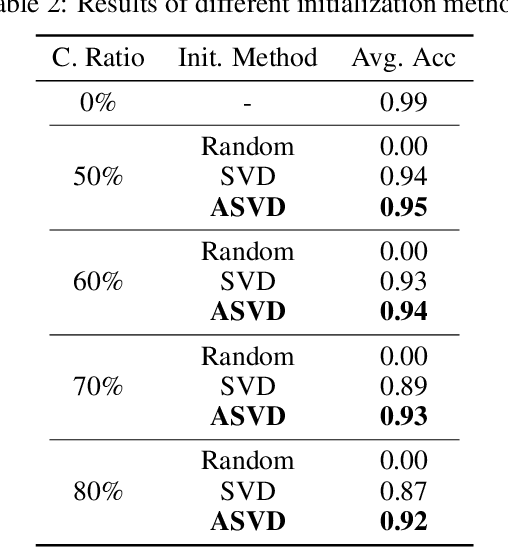
Large Language Models (LLMs) have been widely adopted to process long-context tasks. However, the large memory overhead of the key-value (KV) cache poses significant challenges in long-context scenarios. Existing training-free KV cache compression methods typically focus on quantization and token pruning, which have compression limits, and excessive sparsity can lead to severe performance degradation. Other methods design new architectures with less KV overhead but require significant training overhead. To address the above two drawbacks, we further explore the redundancy in the channel dimension and apply an architecture-level design with minor training costs. Therefore, we introduce CSKV, a training-efficient Channel Shrinking technique for KV cache compression: (1) We first analyze the singular value distribution of the KV cache, revealing significant redundancy and compression potential along the channel dimension. Based on this observation, we propose using low-rank decomposition for key and value layers and storing the low-dimension features. (2) To preserve model performance, we introduce a bi-branch KV cache, including a window-based full-precision KV cache and a low-precision compressed KV cache. (3) To reduce the training costs, we minimize the layer-wise reconstruction loss for the compressed KV cache instead of retraining the entire LLMs. Extensive experiments show that CSKV can reduce the memory overhead of the KV cache by 80% while maintaining the model's long-context capability. Moreover, we show that our method can be seamlessly combined with quantization to further reduce the memory overhead, achieving a compression ratio of up to 95%.