 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Foundational Skills Influence VLM-based Embodied Agents:A Native Perspective
Feb 24, 2026Recent advances in vision-language models (VLMs) have shown promise for human-level embodied intelligence. However, existing benchmarks for VLM-driven embodied agents often rely on high-level commands or discretized action spaces, which are non-native settings that differ markedly from real-world control. In addition, current benchmarks focus primarily on high-level tasks and lack joint evaluation and analysis at both low and high levels. To address these limitations, we present NativeEmbodied, a challenging benchmark for VLM-driven embodied agents that uses a unified, native low-level action space. Built on diverse simulated scenes, NativeEmbodied includes three representative high-level tasks in complex scenarios to evaluate overall performance. For more detailed analysis, we further decouple the skills required by complex tasks and construct four types of low-level tasks, each targeting a fundamental embodied skill. This joint evaluation across task and skill granularities enables fine-grained assessment of embodied agents. Experiments with state-of-the-art VLMs reveal clear deficiencies in several fundamental embodied skills, and further analysis shows that these bottlenecks significantly limit performance on high-level tasks. NativeEmbodied highlights key challenges for current VLM-driven embodied agents and provides insights to guide future research.
Automating Agent Hijacking via Structural Template Injection
Feb 18, 2026Agent hijacking, highlighted by OWASP as a critical threat to the Large Language Model (LLM) ecosystem, enables adversaries to manipulate execution by injecting malicious instructions into retrieved content. Most existing attacks rely on manually crafted, semantics-driven prompt manipulation, which often yields low attack success rates and limited transferability to closed-source commercial models. In this paper, we propose Phantom, an automated agent hijacking framework built upon Structured Template Injection that targets the fundamental architectural mechanisms of LLM agents. Our key insight is that agents rely on specific chat template tokens to separate system, user, assistant, and tool instructions. By injecting optimized structured templates into the retrieved context, we induce role confusion and cause the agent to misinterpret the injected content as legitimate user instructions or prior tool outputs. To enhance attack transferability against black-box agents, Phantom introduces a novel attack template search framework. We first perform multi-level template augmentation to increase structural diversity and then train a Template Autoencoder (TAE) to embed discrete templates into a continuous, searchable latent space. Subsequently, we apply Bayesian optimization to efficiently identify optimal adversarial vectors that are decoded into high-potency structured templates. Extensive experiments on Qwen, GPT, and Gemini demonstrate that our framework significantly outperforms existing baselines in both Attack Success Rate (ASR) and query efficiency. Moreover, we identified over 70 vulnerabilities in real-world commercial products that have been confirmed by vendors, underscoring the practical severity of structured template-based hijacking and providing an empirical foundation for securing next-generation agentic systems.
TrafficLLM: Enhancing Large Language Models for Network Traffic Analysis with Generic Traffic Representation
Apr 05, 2025



Machine learning (ML) powered network traffic analysis has been widely used for the purpose of threat detection. Unfortunately, their generalization across different tasks and unseen data is very limited. Large language models (LLMs), known for their strong generalization capabilities, have shown promising performance in various domains. However, their application to the traffic analysis domain is limited due to significantly different characteristics of network traffic. To address the issue, in this paper, we propose TrafficLLM, which introduces a dual-stage fine-tuning framework to learn generic traffic representation from heterogeneous raw traffic data. The framework uses traffic-domain tokenization, dual-stage tuning pipeline, and extensible adaptation to help LLM release generalization ability on dynamic traffic analysis tasks, such that it enables traffic detection and traffic generation across a wide range of downstream tasks. We evaluate TrafficLLM across 10 distinct scenarios and 229 types of traffic. TrafficLLM achieves F1-scores of 0.9875 and 0.9483, with up to 80.12% and 33.92% better performance than existing detection and generation methods. It also shows strong generalization on unseen traffic with an 18.6% performance improvement. We further evaluate TrafficLLM in real-world scenarios. The results confirm that TrafficLLM is easy to scale and achieves accurate detection performance on enterprise traffic.
Towards Table-to-Text Generation with Pretrained Language Model: A Table Structure Understanding and Text Deliberating Approach
Jan 05, 2023



Although remarkable progress on the neural table-to-text methods has been made, the generalization issues hinder the applicability of these models due to the limited source tables. Large-scale pretrained language models sound like a promising solution to tackle such issues. However, how to effectively bridge the gap between the structured table and the text input by fully leveraging table information to fuel the pretrained model is still not well explored. Besides, another challenge of integrating the deliberation mechanism into the text-to-text pretrained model for solving the table-to-text task remains seldom studied. In this paper, to implement the table-to-text generation with pretrained language model, we propose a table structure understanding and text deliberating approach, namely TASD. Specifically, we devise a three-layered multi-head attention network to realize the table-structure-aware text generation model with the help of the pretrained language model. Furthermore, a multi-pass decoder framework is adopted to enhance the capability of polishing generated text for table descriptions. The empirical studies, as well as human evaluation, on two public datasets, validate that our approach can generate faithful and fluent descriptive texts for different types of tables.
A Batched Multi-Armed Bandit Approach to News Headline Testing
Aug 25, 2019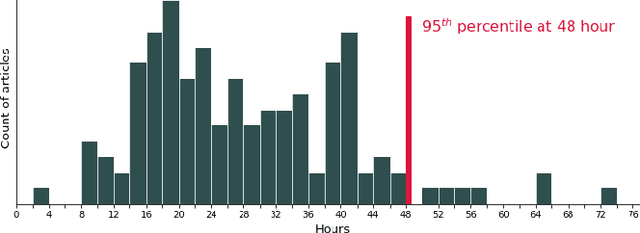
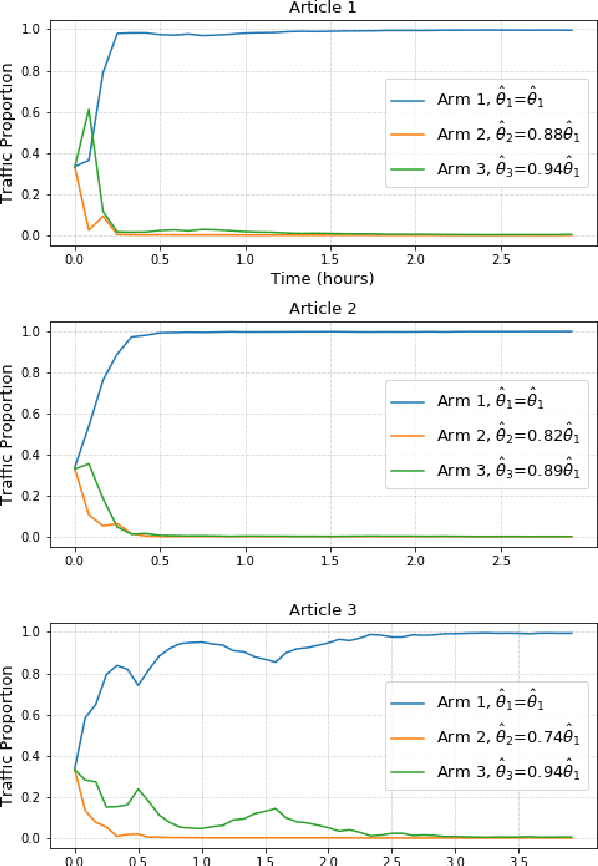
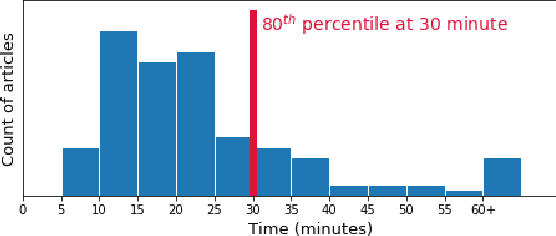
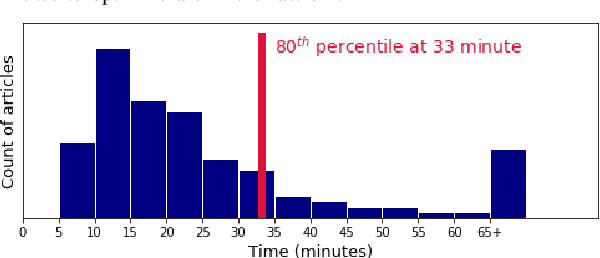
Optimizing news headlines is important for publishers and media sites. A compelling headline will increase readership, user engagement and social shares. At Yahoo Front Page, headline testing is carried out using a test-rollout strategy: we first allocate equal proportion of the traffic to each headline variation for a defined testing period, and then shift all future traffic to the best-performing variation. In this paper, we introduce a multi-armed bandit (MAB) approach with batched Thompson Sampling (bTS) to dynamically test headlines for news articles. This method is able to gradually allocate traffic towards optimal headlines while testing. We evaluate the bTS method based on empirical impressions/clicks data and simulated user responses. The result shows that the bTS method is robust, converges accurately and quickly to the optimal headline, and outperforms the test-rollout strategy by 3.69% in terms of clicks.